
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
锐英源精品开源心得,转载请注明:“锐英源www.wisestudy.cn,孙老师作品,电话13803810136。需要全文内容也请联系孙老师。
OCR是指光学字符识别,它其实是一种图片模式匹配查找。学过编程的朋友对正则多少知道些,OCR有点象正则,不过是把字符串环境换成了图片像素环境。OCR是针对字体进行的学习识别,而神经网络是专业做学习的,两者进行结合学习意义非常大。
A lot of people today are trying to write their own OCR (Optical Character Recognition) System or to improve the quality of an existing one.
This article shows how the use of artificial neural network simplifies development of an optical character recognition application, while achieving highest quality of recognition and good performance.今天很多人都在尝试编写自己的OCR(光学字符识别)系统或者提高现有系统的质量。
本文介绍了如何使用人工神经网络简化光学字符识别应用程序的开发,同时实现最高的识别质量和良好的性能。
Developing proprietary OCR system is a complicated task and requires a lot of effort. Such systems usually are really complicated and can hide a lot of logic behind the code. The use of artificial neural network in OCR applications can dramatically simplify the code and improve quality of recognition while achieving good performance. Another benefit of using neural network in OCR is extensibility of the system – ability to recognize more character sets than initially defined. Most of traditional OCR systems are not extensible enough. Why? Because such task as working with tens of thousands Chinese characters, for example, is not as easy as working with 68 English typed character set and it can easily bring the traditional system to its knees!开发专有的OCR系统是一项复杂的任务,需要付出很多努力。这样的系统通常非常复杂,并且可以隐藏代码背后的许多逻辑。在OCR应用中使用人工神经网络可以显著简化代码并提高识别质量,同时实现良好的性能。在OCR中使用神经网络的另一个好处是系统的可扩展性 - 能够识别比最初定义的更多字符集。大多数传统的OCR系统都不够可扩展。为什么?例如,因为使用数万个汉字这样的任务并不像使用68英文字符集那样容易,它很容易让传统系统瘫痪!
Well, the Artificial Neural Network (ANN) is a wonderful tool that can help to resolve such kind of problems. The ANN is an information-processing paradigm inspired by the way the human brain processes information. Artificial neural networks are collections of mathematical models that represent some of the observed properties of biological nervous systems and draw on the analogies of adaptive biological learning. The key element of ANN is topology. The ANN consists of a large number of highly interconnected processing elements (nodes) that are tied together with weighted connections (links). Learning in biological systems involves adjustments to the synaptic connections that exist between the neurons. This is true for ANN as well. Learning typically occurs by example through training, or exposure to a set of input/output data (pattern) where the training algorithm adjusts the link weights. The link weights store the knowledge necessary to solve specific problems.那么,人工神经网络(ANN)是一个很好的工具,可以帮助解决这类问题。人工神经网络是一种信息处理范式,受人类大脑处理信息的方式的启发。人工神经网络是数学模型的集合,代表了生物神经系统的一些观察到的特性,并借鉴了自适应生物学习的类比。ANN的关键要素是拓扑。ANN由大量高度互连的处理元素(节点)组成,这些元素通过加权连接(链接)连接在一起。在生物系统中学习涉及调整神经元之间存在的突触连接。对于ANN也是如此。学习通常通过例如训练或暴露于一组输入/输出数据(模式)来进行,其中训练算法调整链接权重。链接权重存储解决特定问题所需的知识。
Originated in late 1950's, neural networks didn’t gain much popularity until 1980s – a computer boom era. Today ANNs are mostly used for solution of complex real world problems. They are often good at solving problems that are too complex for conventional technologies (e.g., problems that do not have an algorithmic solution or for which an algorithmic solution is too complex to be found) and are often well suited to problems that people are good at solving, but for which traditional methods are not. They are good pattern recognition engines and robust classifiers, with the ability to generalize in making decisions based on imprecise input data. They offer ideal solutions to a variety of classification problems such as speech, character and signal recognition, as well as functional prediction and system modeling, where the physical processes are not understood or are highly complex. The advantage of ANNs lies in their resilience against distortions in the input data and their capability to learn.起源于20世纪50年代后期,神经网络直到20世纪80年代才开始普及 - 一个计算机繁荣的时代。今天人工神经网络主要用于解决复杂的现实世界问题。他们通常善于解决传统技术过于复杂的问题(例如,没有算法解决方案或算法解决方案过于复杂而无法找到的问题)并且通常非常适合人们擅长的问题解决,但传统方法不是。它们是良好的模式识别引擎和强大的分类器,能够根据不精确的输入数据进行一般化决策。它们为各种分类问题提供理想的解决方案,例如语音,字符和信号识别,以及功能预测和系统建模,物理过程不被理解或高度复杂的地方。人工神经网络的优势在于它们能够抵御输入数据中的扭曲及其学习能力。
In this article I use a sample application from Neuro.NET library to show how to use Backpropagation neural network in a simple OCR application.
Let’s assume you that you already have gone through all image pre-processing routines (resampling, deskew, zoning, blocking etc.) and you already have images of the characters from your document. (In the example I simply generate those images).在本文中,我使用Neuro.NET库中的示例应用程序来演示如何在简单的OCR应用程序中使用Backpropagation神经网络。
让我们假设您已经完成了所有图像预处理程序(重新采样,偏移校正,分区,阻塞等),并且您已经拥有了文档中字符的图像。(在示例中,我只是生成这些图像)。
Let’s construct the network first. In this example I use a Backpropagation neural network. The Backpropagation network is a multilayer perceptron model with an input layer, one or more hidden layers, and an output layer.让我们先构建网络。在这个例子中,我使用Backpropagation神经网络。Backpropagation网络是一个多层感知器模型,具有输入层,一个或多个隐藏层和输出层。
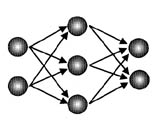
The nodes in the Backpropagation neural network are interconnected via weighted links with each node usually connecting to the next layer up, till the output layer which provides output for the network. The input pattern values are presented and assigned to the input nodes of the input layer. The input values are initialized to values between -1 and 1. The nodes in the next layer receive the input values through links and compute output values of their own, which are then passed to the next layer. These values propagate forward through the layers till the output layer is reached, or put another way, till each output layer node has produced an output value for the network. The desired output for the input pattern is used to compute an error value for each node in the output layer, and then propagated backwards (and here's where the network name comes in) through the network as the delta rule is used to adjust the link values to produce better, the desired output. Once the error produced by the patterns in the training set is below a given tolerance, the training is complete and the network is presented new input patterns and produce an output based on the experience it gained from the learning process.
I will use a library class BackPropagationRPROPNetwork to construct my own OCRNetwork.
Backpropagation神经网络中的节点通过加权链路互连,每个节点通常连接到下一层,直到输出层为网络提供输出。输入模式值被呈现并分配给输入层的输入节点。输入值初始化为-1到1之间的值。下一层中的节点通过链接接收输入值并计算它们自己的输出值,然后传递给下一层。这些值向前传播通过层直到达到输出层,或换句话说,直到每个输出层节点产生网络的输出值。输入模式的所需输出用于计算输出层中每个节点的错误值,然后向后传播(此处为' 网络名称来自网络,因为delta规则用于调整链接值以产生更好的所需输出。一旦训练集中的模式产生的错误低于给定的容差,训练就完成了,网络将呈现新的输入模式,并根据从学习过程中获得的经验产生输出。
我将使用库类BackPropagationRPROPNetwork来构建自己的类OCRNetwork。
//Inherit form Backpropagation neural network
public class OCRNetwork: BackPropagationRPROPNetwork
{
//Override method of the base class in order to implement our
//own training method
public override void Train(PatternsCollection patterns)
{
...
}
}
I override the Train method of the base class to implement my own training method. Why do I need to do it? I do it because of one simple reason: the training progress of the network is measured by quality of produced result and speed of training. You have to establish the criteria when the quality of network output is acceptable for you and when you can stop the training process. The implementation I provide here is proven (based on my experience) to be fast and accurate. I decided that I can stop the training process when network is able to recognize all of the patterns, without a single error. So, here is the implementation of my training method.我重写Train基类的方法来实现我自己的训练方法。我为什么需要这样做?我之所以这样做是因为一个简单的原因:网络的训练进度是通过生成结果的质量和训练的速度来衡量的。当您可以接受网络输出质量以及何时可以停止训练过程时,您必须建立标准。我在这里提供的实现证明(根据我的经验)快速准确。当网络能够识别所有模式时,我决定停止训练过程,没有一个错误。所以,这是我的训练方法的实现。
public override void Train(PatternsCollection patterns)
{ //Current iteration number
if (patterns != null)
{
double error = 0;
int good = 0;
// Train until all patterns are correct
while (good < patterns.Count)
{
good = 0;
for (int i = 0; i<patterns.Count; i++)
{
//Set the input values of the network
for (int k = 0; k<NodesInLayer(0); k++)
nodes[k].Value = patterns[i].Input[k];
//Run the network
this.Run();
//Set the expected result
for (int k = 0;k< this.OutputNodesCount;k++)
this.OutputNode(k).Error = patterns[i].Output[k];
//Make the network to remember corresponding output
//values. (Teach the network)
this.Learn();
//See if network did produced correct result during
//this iteration
if (BestNodeIndex == OutputPatternIndex(patterns[i]))
good++;
}
//Adjust weights of the links in the network to their
//average value. (An epoch training technique)
foreach (NeuroLink link in links)
((EpochBackPropagationLink)link).Epoch(patterns.Count);
}
}
}
Also, I have implemented a BestNodeIndex property that returns the index of the node having maximum value and having the minimal error. An OutputPatternIndex method returns the index of the pattern output element having value of 1. If those indices are matched – the network has produced correct result. Here is how the BestNodeIndex implementation looks like:此外,我已经实现了一个BestNodeIndex属性,该属性返回具有最大值并具有最小错误的节点的索引。OutputPatternIndex方法返回的1图案输出具有值元素的索引,如果这些索引匹配-网络已经产生正确的结果。以下是BestNodeIndex实现的方式:
public int BestNodeIndex
{
get {
int result = -1;
double aMaxNodeValue = 0;
double aMinError = double.PositiveInfinity;
for (int i = 0; i< this.OutputNodesCount;i++)
{
NeuroNode node = OutputNode(i);
//Look for a node with maximum value or lesser error
if ((node.Value > aMaxNodeValue)||
((node.Value >= aMaxNodeValue)&&(node.Error <aMinError)))
{
aMaxNodeValue = node.Value;
aMinError = node.Error;
result = i;
}
}
return result;
}
}
As simple as it gets I create the instance of the neural network. The network has one constructor parameter – integer array describing number of nodes in each layer of the network. First layer in the network is an input layer. The number of elements in this layer corresponds to number of elements in input pattern and is equal to number of elements in digitized image matrix (we will talk about it later). The network may have multiple middle layers with different number of nodes in each layer. In this example I use only one layer and apply “not official rule of thumb” to determine number of nodes in this layer:尽可能简单,我创建了神经网络的实例。网络有一个构造函数参数 - 整数数组,描述网络每层中的节点数。网络中的第一层是输入层。该层中的元素数量对应于输入模式中的元素数量,并且等于数字化图像矩阵中的元素数量(稍后我们将讨论它)。网络可以具有多个中间层,每层中具有不同数量的节点。在这个例子中,我只使用一个图层并应用“非官方经验法则”来确定该图层中的节点数量:
NodesNumber = (InputsCount+OutputsCount) / 2
Note: You can experiment by adding more middle layers and using different number of nodes in there - just to see how it will affect the training speed and recognition quality of the network.
The last layer in the network is an output layer. This is the layer where we look for the results. I define the number of nodes in this layer equal to a number of characters that we going to recognize.
注意:您可以通过添加更多中间层并使用不同数量的节点进行试验 - 只是为了了解它将如何影响网络的训练速度和识别质量。
网络中的最后一层是输出层。这是我们寻找结果的层。我定义此层中的节点数等于我们要识别的字符数。
//Create an instance of the network
backpropNetwork = new OCRNetwork(new int[3] {aMatrixDim * aMatrixDim,
(aMatrixDim * aMatrixDim + aCharsCount)/2, aCharsCount});
Now let's talk about the training patterns. Those patterns will be used for teaching the neural network to recognize the images. Basically, each training pattern consists of two single-dimensional arrays of float numbers – Inputs and Outputs arrays.现在让我们谈谈训练模式。这些模式将用于教导神经网络识别图像。基本上,每个训练模式由两个浮点数的单维数组Inputs和Outputs数组组成。
/// <summary>
/// A class representing single training pattern and is used to train a
/// neural network. Contains input data and expected results arrays.
/// </summary>
public class Pattern: NeuroObject
{
private double[] inputs, outputs;
...
}
The Inputs array contains your input data. In our case it is a digitized representation of the character's image. Under “digitizing” the image I mean process of creating a brightness (or absolute value of the color vector-whatever you choose) map of the image. To create this map I split the image into squares and calculate average value of each square. Then I store those values into the array.该Inputs数组包含您的输入数据。在我们的例子中,它是角色图像的数字化表示。在“数字化”图像下,我指的是创建亮度(或颜色矢量的绝对值 - 无论你选择什么)图像的过程。要创建此地图,我将图像拆分为正方形并计算每个正方形的平均值。然后我将这些值存储到数组中。

I have implemented CharToDoubleArray method of the network to digitize the image. There I use an absolute value of the color for each element of the matrix. (No doubt that you can use other techniques there…) After the image is digitized, I have to scale-down the results in order to fit them into a range from -1 ..1 to comply with input values range of the network. To do this I wrote a Scale method, where I look for the maximum element value of the matrix and then divide all elements of the matrix by it. So, implementation of CharToDoubleArraylooks like this:我已经实现网络的CharToDoubleArray方法来数字化图像。在那里,我使用矩阵的每个元素的颜色的绝对值。(毫无疑问,你可以使用其他技术......)在图像数字化之后,我必须缩小结果以使它们适合-1.1的范围,以符合网络的输入值范围。为此,我写了一个Scale方法,在那里我寻找矩阵的最大元素值,然后用它来划分矩阵的所有元素。所以,实现CharToDoubleArray看起来像这样:
//aSrc – an image of the character
//aArrayDim – dimension of the pattern matrix
//calculate image quotation X step
double xStep = (double)aSrc.Width/(double)aArrayDim;
//calculate image quotation Y step
double yStep = (double)aSrc.Height/(double)aArrayDim;
double[] result = new double[aMatrixDim*aMatrixDim ];
for (int i=0; i<aSrc.Width; i++)
for (int j=0;j<aSrc.Height;j++)
{
//calculate matrix address
int x = (int)(i/xStep);
int y = (int)(j/yStep);
//Get the color of the pixel
Color c = aSrc.GetPixel(i,j);
//Absolute value of the color, but I guess, it is possible to
//use the B component of Alpha color space too...
result[y*x+y]+=Math.Sqrt(c.R*c.R+c.B*c.B+c.G*c.G);
}
//Scale the matrix to fit values into a range from 0..1 (required by
//ANN) In this method we look for a maximum value of the element
//and then divide all elements of the matrix by this maximum value.
return Scale(result);;
The Outputs array of the pattern represents an expected result – the result that network will use during the training. There are as many elements in this array as many characters we going to recognize. So, for instance, to teach the network to recognize English letters from “A” to “Z” we will need 25 elements in the Outputs array. Make it 50 if you decide to include lower case letters. Each element corresponds to a single letter. The Inputs of each pattern are set to a digitized image data and a corresponding element in the Outputs array to 1, so network will know which output (letter) corresponds to input data. The method CreateTrainingPatternsdoes this job for me.所述Outputs图案的阵列表示的预期结果-其结果是在训练期间网络将使用。这个数组中的元素数量与我们要识别的字符数一样多。因此,例如,要教网络识别从“A”到“Z”的英文字母,我们将需要Outputs数组中的25个元素。如果您决定包含小写字母,请将其设为50。每个元素对应一个字母。Inputs的每个模式都设定为数字化图像数据和在对应的元件Outputs阵列1,因此网络将知道哪个输出(字母)对应于输入数据。方法CreateTrainingPatterns为我完成了这项工作。
public PatternsCollection CreateTrainingPatterns(Font font) {
//Create pattern collection
// As many inputs (examples) as many elements in digitized image matrix
// As many outputs as many characters we going to recognize.
PatternsCollection result = new PatternsCollection(aCharsCount,
aMatrixDim * aMatrixDim, aCharsCount);
// generate one pattern for each character
for (int i= 0; i<aCharsCount; i++)
{
//CharToDoubleArray creates an image of the character and digitizes it.
//You can change this method to pass actual the image of the character
double[] aBitMatrix = CharToDoubleArray(Convert.ToChar(aFirstChar + i),
font, aMatrixDim, 0);
//Assign matrix value as input to the pattern
for (int j = 0; j<aMatrixDim * aMatrixDim; j++)
result[i].Input[j] = aBitMatrix[j];
//Output value set to 1 for corresponding character.
//Rest of the outputs are set to 0 by default.
result[i].Output[i] = 1;
}
return result;
}.
To start training process of the network simple call the Train method and pass your training patterns in it.要开始网络的训练过程,请简单地调用该Train方法并将训练模式传递给它。
//Train the network backpropNetwork.Train(trainingPatterns);
Normally, an execution flow will leave this method when training is complete, but in some cases it could stay there forever (!).The Train method is currently implemented relying only on one fact: the network training will be completed sooner or later. Well, I admit - this is wrong assumption and network training may never complete. The most “popular” reasons for neural network training failure are:通常情况下,执行流程将在训练完成后离开此方法,但在某些情况下,它可以永久保留在那里(!)。该Train方法目前仅依靠一个事实实现:网络训练迟早会完成。好吧,我承认 - 这是错误的假设,网络训练可能永远不会完成。神经网络训练失败的最“流行”原因是:
Training never completes because: |
Possible solution |
1. The network topology is too simple to handle amount of training patterns you provide. You will have to create bigger network. |
Add more nodes into middle layer or add more middle layers to the network. |
2. The training patterns are not clear enough, not precise or are too complicated for the network to differentiate them. |
As a solution you can clean the patterns or you can use different type of network /training algorithm. Also, you cannot train the network to guess next winning lottery numbers... :-) |
3. Your training expectations are too high and/or not realistic. |
Lower your expectations. The network could be never 100% "sure" |
4. No reason |
Check the code! |
Most of those reasons are very easy to resolve and it is a good subject for a future article. Meanwhile, we can enjoy the results.
培训从未完成,因为: |
可能的方案 |
1.网络拓扑过于简单,无法处理您提供的训练模式。您将不得不创建更大的网络。 |
将更多节点添加到中间层或向网络添加更多中间层。 |
2.训练模式不够清晰,不够精确或太复杂,网络无法区分它们。 |
作为解决方案,您可以清理模式,也可以使用不同类型的网络/培训算法。此外,你不能训练网络猜测下一个中奖彩票...... :-) |
3.你的训练期望太高和/或不现实。 |
降低你的期望。网络永远不会100%“肯定” |
没有理由 |
检查代码! |
大多数这些原因很容易解决,这是未来文章的一个很好的主题。同时,我们可以享受结果。
Now we can see what the network has learned. Following code fragment shows how to use trained neural network in your OCR application.现在我们可以看到网络学到了什么。以下代码片段显示了如何在OCR应用程序中使用经过训练的神经网络。
//Get your input data
double[] aInput = ... (your digitized image of the character)
//Load the data into the network
for (int i = 0; i< backpropNetwork.InputNodesCount;i++)
backpropNetwork.InputNode(i).Value = aInput[i];
//Run the network
backpropNetwork.Run();
//Get result from the network and convert it to a character
return Convert.ToChar(aFirstChar + backpropNetwork.BestNodeIndex).ToString();
In order to use the network you have to load your data into input layer. Then use the Run method to let the network process your data. Finally, get your results out from output nodes of the network and analyze those (The BestNodeIndex property I created in OCRNetwork class does this job for me).要使用网络,您必须将数据加载到输入层。然后使用该Run方法让网络处理您的数据。最后,从网络的输出节点获取结果并分析(我在OCRNetwork类里创建的BestNodeIndex属性为我做这个工作)。