
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
锐英源精品开源心得,转载请注明:“锐英源www.wisestudy.cn,孙老师作品,电话13803810136。需要全文内容也请联系孙老师。
Template matching is an image processing problem to find the location of an object using a template image in another search image when its pose (X, Y, θ) is unknown. In this article, we implement an algorithm that uses an object’s edge information for recognizing the object in the search image.模板匹配是图像处理问题,当对象的轮廓(X,Y,θ)未知时,可以使用模板图像在另一个搜索图像中查找对象的位置。在本文中,我们实现了一种算法,该算法使用对象的边缘信息来识别搜索图像中的对象。
Template matching is inherently a tough problem due to its speed and reliability issues. The solution should be robust against brightness changes when an object is partially visible or mixed with other objects, and most importantly, the algorithm should be computationally efficient. There are mainly two approaches to solve this problem, gray value based matching (or area based matching) and feature based matching (non area based).模板匹配由于其速度和可靠性问题而固有地是一个棘手的问题。当一个对象部分可见或与其他对象混合时,该解决方案应具有抵抗亮度变化的鲁棒性,最重要的是,该算法应具有计算效率。解决此问题的方法主要有两种,基于灰度值的匹配(或基于区域的匹配)和基于特征的匹配(非基于区域)。
Gray value based approach: In gray value based matching, the Normalized Cross Correlation (NCC) algorithm is known from old days. This is typically done at every step by subtracting the mean and dividing by the standard deviation. The cross correlation of template t(x, y) with a sub image f(x, y) is:基于灰度值的方法:在基于灰度值的匹配中,从过去就知道归一化互相关(NCC)算法。通常,在每个步骤中均应减去平均值并除以标准偏差。模板t(x,y)与子图像f(x,y)的互相关为:
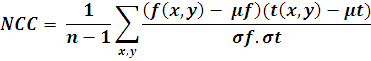
Where n is the number of pixels in t(x, y) and f(x, y). [Wiki]其中n是t(x,y)和f(x,y)中的像素数
Though this method is robust against linear illumination changes, the algorithm will fail when the object is partially visible or the object is mixed with other objects. Moreover, this algorithm is computationally expensive since it needs to compute the correlation between all the pixels in the template image to the search image.尽管此方法对线性照度变化具有鲁棒性,但当对象部分可见或与其他对象混合时,该算法将失败。而且,由于该算法需要计算模板图像中所有像素与搜索图像之间的相关性,因此该算法在计算上是昂贵的。
Feature based approach: Several methods of feature based template matching are being used in the image processing domain. Like edge based object recognition where the object edges are features for matching, in Generalized Hough transform, an object’s geometric features will be used for matching.
In this article, we implement an algorithm that uses an object’s edge information for recognizing the object in a search image. This implementation uses the Open-Source Computer Vision library as a platform.
基于特征的方法:在图像处理领域中使用了几种基于特征的模板匹配方法。类似于基于边缘的对象识别,其中对象边缘是要匹配的特征,在广义霍夫变换中,对象的几何特征将用于匹配。
在本文中,我们实现了一种算法,该算法使用对象的边缘信息来识别搜索图像中的对象。此实现使用开源计算机视觉库作为平台。
We are using OpenCV 2.0 and Visual studio 2008 to develop this code. To compile the example code, we need to install OpenCV.
OpenCV can be downloaded free from here. OpenCV (Open Source Computer Vision) is a library of programming functions for real time computer vision. Download OpenCV and install it in your system. Installation information can be read from here.
We need to configure our Visual Studio environment. This information can be read from here.
我们正在使用OpenCV 2.0和Visual Studio 2008来开发此代码。要编译示例代码,我们需要安装OpenCV。
可以从此处免费下载OpenCV 。OpenCV的(开放源码ç动态数值V ision)是编程函数即时计算机视觉库。下载OpenCV并将其安装在系统中。可以从此处阅读安装信息。
我们需要配置我们的Visual Studio环境。这些信息可以从这里阅读。
Here, we are explaining an edge based template matching technique. An edge can be defined as points in a digital image at which the image brightness changes sharply or has discontinuities. Technically, it is a discrete differentiation operation, computing an approximation of the gradient of the image intensity function.
There are many methods for edge detection, but most of them can be grouped into two categories: search-based and zero-crossing based. The search-based methods detect edges by first computing a measure of edge strength, usually a first-order derivative expression such as the gradient magnitude, and then searching for local directional maxima of the gradient magnitude using a computed estimate of the local orientation of the edge, usually the gradient direction. Here, we are using such a method implemented by Sobel known as Sobel operator. The operator calculates the gradient of the image intensity at each point, giving the direction of the largest possible increase from light to dark and the rate of change in that direction.
We are using these gradients or derivatives in X direction and Y direction for matching.
This algorithm involves two steps. First, we need to create an edge based model of the template image, and then we use this model to search in the search image.
在这里,我们将说明基于边缘的模板匹配技术。边缘可以定义为数字图像中图像亮度急剧变化或不连续的点。从技术上讲,它是一个离散的微分运算,它计算图像强度函数的梯度的近似值。
边缘检测方法很多,但大多数可以分为两类:基于搜索和基于零交叉。基于搜索的方法通过首先计算边缘强度的量度(通常是一阶导数表达式(例如梯度幅度))来检测边缘,然后使用计算出的边缘方向的估计值搜索梯度幅度的局部方向最大值。边缘,通常是渐变方向。在这里,我们使用由Sobel实现的称为Sobel运算符的方法。操作员计算每个点上图像强度的梯度,从而给出从亮到暗的最大可能增加的方向以及该方向上的变化率。
我们将这些梯度或X方向和Y方向的导数用于匹配。
该算法涉及两个步骤。首先,我们需要创建模板图像的基于边缘的模型,然后使用该模型在搜索图像中进行搜索。
We first create a data set or template model from the edges of the template image that will be used for finding the pose of that object in the search image.
Here we are using a variation of Canny’s edge detection method to find the edges. You can read more on Canny’s edge detection here. For edge extraction, Canny uses the following steps:
我们首先从模板图像的边缘创建一个数据集或模板模型,该数据集或模板模型将用于在搜索图像中查找该对象的姿态。
在这里,我们使用Canny边缘检测方法的一种变体来查找边缘。您可以在此处阅读有关Canny边缘检测的更多信息。对于边缘提取,Canny使用以下步骤:
Use the Sobel filter on the template image which returns the gradients in the X (Gx) and Y (Gy) direction. From this gradient, we will compute the edge magnitude and direction using the following formula:在模板图像上使用Sobel滤镜,该滤镜返回X(Gx)和Y(Gy)方向上的渐变。根据此梯度,我们将使用以下公式计算边缘大小和方向:
![]()
![]()
We are using an OpenCV function to find these values.我们正在使用OpenCV函数查找这些值。
cvSobel( src, gx, 1,0, 3 ); //gradient in X direction
cvSobel( src, gy, 0, 1, 3 ); //gradient in Y direction
for( i = 1; i < Ssize.height-1; i++ )
{
for( j = 1; j < Ssize.width-1; j++ )
{
_sdx = (short*)(gx->data.ptr + gx->step*i);
_sdy = (short*)(gy->data.ptr + gy->step*i);
fdx = _sdx[j]; fdy = _sdy[j];
// read x, y derivatives
//Magnitude = Sqrt(gx^2 +gy^2)
MagG = sqrt((float)(fdx*fdx) + (float)(fdy*fdy));
//Direction = invtan (Gy / Gx)
direction =cvFastArctan((float)fdy,(float)fdx);
magMat[i][j] = MagG;
if(MagG>MaxGradient)
MaxGradient=MagG;
// get maximum gradient value for normalizing.
// get closest angle from 0, 45, 90, 135 set
if ( (direction>0 && direction < 22.5) ||
(direction >157.5 && direction < 202.5) ||
(direction>337.5 && direction<360) )
direction = 0;
else if ( (direction>22.5 && direction < 67.5) ||
(direction >202.5 && direction <247.5) )
direction = 45;
else if ( (direction >67.5 && direction < 112.5)||
(direction>247.5 && direction<292.5) )
direction = 90;
else if ( (direction >112.5 && direction < 157.5)||
(direction>292.5 && direction<337.5) )
direction = 135;
else
direction = 0;
orients[count] = (int)direction;
count++;
}
}
Once the edge direction is found, the next step is to relate the edge direction that can be traced in the image. There are four possible directions describing the surrounding pixels: 0 degrees, 45 degrees, 90 degrees, and 135 degrees. We assign all the directions to any of these angles.一旦找到边缘方向,下一步就是关联可以在图像中跟踪的边缘方向。有四个可能的方向来描述周围的像素:0度,45度,90度和135度。我们将所有方向分配给这些角度中的任何一个。
After finding the edge direction, we will do a non-maximum suppression algorithm. Non-maximum suppression traces the left and right pixel in the edge direction and suppresses the current pixel magnitude if it is less than the left and right pixel magnitudes. This will result in a thin image.找到边缘方向后,我们将执行非最大抑制算法。非最大抑制沿边缘方向跟踪左右像素,如果当前像素幅度小于左右像素幅度,则将其抑制。这将导致图像变薄。
for( i = 1; i < Ssize.height-1; i++ )
{
for( j = 1; j < Ssize.width-1; j++ )
{
switch ( orients[count] )
{
case 0:
leftPixel = magMat[i][j-1];
rightPixel = magMat[i][j+1];
break;
case 45:
leftPixel = magMat[i-1][j+1];
rightPixel = magMat[i+1][j-1];
break;
case 90:
leftPixel = magMat[i-1][j];
rightPixel = magMat[i+1][j];
break;
case 135:
leftPixel = magMat[i-1][j-1];
rightPixel = magMat[i+1][j+1];
break;
}
// compare current pixels value with adjacent pixels
if (( magMat[i][j] < leftPixel ) || (magMat[i][j] < rightPixel ) )
(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;
Else
(nmsEdges->data.ptr + nmsEdges->step*i)[j]=
(uchar)(magMat[i][j]/MaxGradient*255);
count++;
}
}
Doing the threshold with hysteresis requires two thresholds: high and low. We apply a high threshold to mark out thosee edges we can be fairly sure are genuine. Starting from these, using the directional information derived earlier, other edges can be traced through the image. While tracing an edge, we apply the lower threshold, allowing us to trace faint sections of edges as long as we find a starting point.具有滞后性的阈值需要两个阈值:高和低。我们采用较高的阈值来标记那些我们可以确定是真实的边缘。从这些开始,使用先前导出的方向信息,可以在图像中跟踪其他边缘。跟踪边缘时,我们应用较低的阈值,只要我们找到起点,就可以跟踪边缘的模糊部分。
_sdx = (short*)(gx->data.ptr + gx->step*i);
_sdy = (short*)(gy->data.ptr + gy->step*i);
fdx = _sdx[j]; fdy = _sdy[j];
MagG = sqrt(fdx*fdx + fdy*fdy); //Magnitude = Sqrt(gx^2 +gy^2)
DirG =cvFastArctan((float)fdy,(float)fdx); //Direction = tan(y/x)
////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]= MagG;
flag=1;
if(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j]) < maxContrast)
{
if(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j])< minContrast)
{
(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;
flag=0; // remove from edge
////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]=0;
}
else
{ // if any of 8 neighboring pixel is not greater than max contraxt remove from edge
if( (((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j-1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j+1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j-1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j+1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j-1]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j]) < maxContrast) &&
(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j+1]) < maxContrast))
{
(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;
flag=0;
////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]=0;
}
}
}
After extracting the edges, we save the X and Y derivatives of the selected edges along with the coordinate information as the template model. These coordinates will be rearranged to reflect the start point as the center of gravity.提取边缘后,我们将所选边缘的X和Y导数以及坐标信息保存为模板模型。将重新排列这些坐标,以将起点反映为重心。
The next task in the algorithm is to find the object in the search image using the template model. We can see the model we created from the template image which contains a set of points:该算法的下一个任务是使用模板模型在搜索图像中找到对象。我们可以看到从模板图像创建的模型,该模型包含一组点: ![]() , and its gradients in X and Y direction 其在X和Y方向上的梯度
, and its gradients in X and Y direction 其在X和Y方向上的梯度![]() , where i = 1…n, n is the number of elements in the Template (T) data set.其中i = 1…n,n是模板(T)数据集中的元素数。
, where i = 1…n, n is the number of elements in the Template (T) data set.其中i = 1…n,n是模板(T)数据集中的元素数。
We can also find the gradients in the search image (S) 我们还可以在搜索图像(S)中找到梯度![]() , where u = 1...number of rows in the search image, v = 1… number of columns in the search image.其中u = 1 ...搜索图像中的行数,v = 1 ...搜索图像中的列数。
, where u = 1...number of rows in the search image, v = 1… number of columns in the search image.其中u = 1 ...搜索图像中的行数,v = 1 ...搜索图像中的列数。
In the matching process, the template model should be compared to the search image at all locations using a similarity measure. The idea behind similarity measure is to take the sum of all normalized dot products of gradient vectors of the template image and search the image over all points in the model data set. This results in a score at each point in the search image. This can be formulated as follows:在匹配过程中,应使用相似性度量将模板模型与所有位置的搜索图像进行比较。相似性度量背后的想法是对模板图像的梯度向量的所有归一化点积求和,然后在模型数据集中的所有点上搜索图像。这会在搜索图像的每个点上产生一个分数。可以表述为:
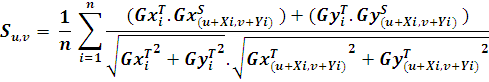
In case there is a perfect match between the template model and the search image, this function will return a score 1. The score corresponds to the portion of the object visible in the search image. In case the object is not present in the search image, the score will be 0.如果模板模型与搜索图像之间存在完美匹配,则此函数将返回分数1。该分数对应于对象在搜索图像中可见的部分。如果搜索图像中不存在该对象,则分数将为0。
cvSobel( src, Sdx, 1, 0, 3 ); // find X derivatives
cvSobel( src, Sdy, 0, 1, 3 ); // find Y derivatives
for( i = 0; i < Ssize.height; i++ )
{
for( j = 0; j < Ssize.width; j++ )
{
partialSum = 0; // initilize partialSum measure
for(m=0;m<noOfCordinates;m++)
{
curX = i + cordinates[m].x ; // template X coordinate
curY = j + cordinates[m].y ; // template Y coordinate
iTx = edgeDerivativeX[m]; // template X derivative
iTy = edgeDerivativeY[m]; // template Y derivative
if(curX<0 ||curY<0||curX>Ssize.height-1 ||curY>Ssize.width-1)
continue;
_Sdx = (short*)(Sdx->data.ptr + Sdx->step*(curX));
_Sdy = (short*)(Sdy->data.ptr + Sdy->step*(curX));
iSx=_Sdx[curY]; // get curresponding X derivative from source image
iSy=_Sdy[curY];// get curresponding Y derivative from source image
if((iSx!=0 || iSy!=0) && (iTx!=0 || iTy!=0))
{
//partial Sum = Sum of(((Source X derivative* Template X drivative)
//+ Source Y derivative * Template Y derivative)) / Edge
//magnitude of(Template)* edge magnitude of(Source))
partialSum = partialSum + ((iSx*iTx)+(iSy*iTy))*
(edgeMagnitude[m] * matGradMag[curX][curY]);
}
In practical situations, we need to speed up the searching procedure. This can be achieved using various methods. The first method is using the property of averaging. When finding the similarity measure, we need not evaluate for all points in the template model if we can set a minimum score (Smin) for the similarity measure. For checking the partial score Su,v at a particular point J, we have to find the partial sum Sm. Sm at point m can be defines as follows:在实际情况下,我们需要加快搜索过程。这可以使用各种方法来实现。第一种方法是使用平均属性。找到相似性度量时,如果我们可以为相似性度量设置最低分数(S min),则无需评估模板模型中的所有点。为了检查在特定点J处的部分分数S u,v,我们必须找到部分和Sm。m点处的Sm可以定义如下:
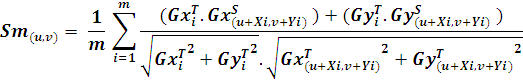
It is evident that the remaining terms of the sum are smaller or equal to 1. So we can stop the evaluation if显然,和的其余项小于或等于1。因此,如果,我们可以停止求值![]() .
.
Another criterion can be that the partial score at any point should be greater than the minimum score. I.e.另一个标准可以是在任何点上的部分分数应大于最小分数。即, ,![]() . When this condition is used, matching will be extremely fast. But the problem is, if the missing part of the object is checked first, the partial sum will be low. In that case, that instance of the object will not be considered as a match. We can modify this with another criterion where we check the first part of the template model with a safe stopping criteria and the remaining with a hard criteria, 使用此条件时,匹配将非常快。但是问题是,如果首先检查对象的缺失部分,则部分和会很低。在这种情况下,该对象的实例将不被视为匹配项。我们可以使用另一个条件修改此条件,在该条件下,我们使用安全的停止条件检查模板模型的第一部分,并使用严格的条件检查其余部分,
. When this condition is used, matching will be extremely fast. But the problem is, if the missing part of the object is checked first, the partial sum will be low. In that case, that instance of the object will not be considered as a match. We can modify this with another criterion where we check the first part of the template model with a safe stopping criteria and the remaining with a hard criteria, 使用此条件时,匹配将非常快。但是问题是,如果首先检查对象的缺失部分,则部分和会很低。在这种情况下,该对象的实例将不被视为匹配项。我们可以使用另一个条件修改此条件,在该条件下,我们使用安全的停止条件检查模板模型的第一部分,并使用严格的条件检查其余部分,![]() . The user can specify a greediness parameter (g) where the fraction of the template model is examined with a hard criteria. So that if g=1, all points in the template model are checked with the hard criteria, and if g=0, all the points will be checked with a safe criteria only. We can formulate this procedure as follows.用户可以指定贪婪性参数(g),在其中使用硬性标准检查模板模型的分数。因此,如果g = 1,则使用硬标准检查模板模型中的所有点,如果g = 0,则仅使用安全标准检查所有点。我们可以将这个过程制定如下。
. The user can specify a greediness parameter (g) where the fraction of the template model is examined with a hard criteria. So that if g=1, all points in the template model are checked with the hard criteria, and if g=0, all the points will be checked with a safe criteria only. We can formulate this procedure as follows.用户可以指定贪婪性参数(g),在其中使用硬性标准检查模板模型的分数。因此,如果g = 1,则使用硬标准检查模板模型中的所有点,如果g = 0,则仅使用安全标准检查所有点。我们可以将这个过程制定如下。
The evaluation of the partial score can be stopped at:可以在以下位置停止对部分分数的评估:
![]()
// stoping criterias to search for model
double normMinScore = minScore /noOfCordinates; // precompute minumum score
double normGreediness = ((1- greediness * minScore)/(1-greediness)) /noOfCordinates;
// precompute greedniness
sumOfCoords = m + 1;
partialScore = partialSum /sumOfCoords ;
// check termination criteria
// if partial score score is less than the score than
// needed to make the required score at that position
// break serching at that coordinate.
if( partialScore < (MIN((minScore -1) +
normGreediness*sumOfCoords,normMinScore* sumOfCoords)))
break;
This similarity measure has several advantages: the similarity measure is invariant to non-linear illumination changes because all gradient vectors are normalized. Since there is no segmentation on edge filtering, it will show the true invariance against arbitrary changes in illumination. More importantly, this similarity measure is robust when the object is partially visible or mixed with other objects.这种相似性度量具有几个优点:相似性度量对于非线性照明变化是不变的,因为所有梯度矢量都已归一化。由于在边缘滤波上没有分割,因此它将针对光照的任意变化显示出真正的不变性。更重要的是,当对象部分可见或与其他对象混合时,这种相似性度量是可靠的。
There are various enhancements possible for this algorithm. For speeding up the search process further, a pyramidal approach can be used. In this case, the search is started at low resolution with a small image size. This corresponds to the top of the pyramid. If the search is successful at this stage, the search is continued at the next level of the pyramid, which represents a higher resolution image. In this manner, the search is continued, and consequently, the result is refined until the original image size, i.e., the bottom of the pyramid is reached.
Another enhancement is possible by extending the algorithm for rotation and scaling. This can be done by creating template models for rotation and scaling and performing search using all these template models.此算法可能有各种增强。为了进一步加快搜索过程,可以使用金字塔方法。在这种情况下,搜索将以低分辨率和小图像尺寸开始。这对应于金字塔的顶部。如果在此阶段搜索成功,则在代表更高分辨率图像的金字塔的下一个级别继续搜索。以这种方式,继续搜索,结果,结果被细化,直到达到原始图像大小,即金字塔的底部。
通过扩展旋转和缩放算法,可以实现另一种增强。这可以通过创建用于旋转和缩放的模板模型并使用所有这些模板模型执行搜索来完成。