政企荣誉
 亚马逊语音识别合作
亚马逊语音识别合作
意向种子企业,小语种方向 政府推荐参加资本力量
政府推荐参加资本力量
1+6融资活动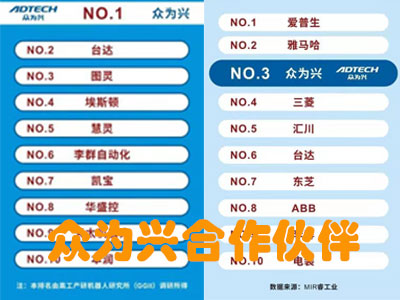 上市公司众为兴
上市公司众为兴
合作伙伴 河南职教中心
河南职教中心
成人学历和能力培训合作联盟成员

精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
亚马逊语音识别合作政府推荐参加资本力量上市公司众为兴河南职教中心人的智能是用感觉分析自然和社会,做出决定的本能和智能。而人工智能是用数据来分析自然和社会,做出决定的运算。科学家和计算机专家在人工智能上经过不懈努力,已经在部分场景里达到了局部成熟。这个局部就是游戏,有些开放模型和无规模模型已经能很好地分析游戏和电子游戏,这些也有公开的文章,本文结合pytorch处理马里奥的游戏智能来引导介绍下游戏智能,既是对学习的总结,也是给大家的学习心得,共同提高。
首先,人是有一些分析经验在大脑里,pytroch对应的经验库是gym库,生成的经验环境语句有:
# Initialize Super Mario environment
env = gym_super_mario_bros.make("SuperMarioBros-1-1-v0")
# Limit the action-space to
# 0\. walk right
# 1\. jump right
env = JoypadSpace(env, [["right"], ["right", "A"]])
里面的"SuperMarioBros-1-1-v0"字眼里有Mario,表明和马里奥游戏对应。
环境经验是原始经验,经过下面的包装变成人工智能接受的数据:
# Apply Wrappers to environment
env = SkipFrame(env, skip=4)
env = GrayScaleObservation(env)
env = ResizeObservation(env, shape=84)
env = FrameStack(env, num_stack=4)
然后使用马里奥游戏智能模型来处理接受数据,游戏智能模型的原型如下:
class Mario:
def __init__():
pass
def act(self, state):
"""Given a state, choose an epsilon-greedy action"""
pass
def cache(self, experience):
"""Add the experience to memory"""
pass
def recall(self):
"""Sample experiences from memory"""
pass
def learn(self):
"""Update online action value (Q) function with a batch of experiences"""
Pass
里面cache是保存经验,recall是提取经验,learn是用经验学习,学习成果反应到运作act。具体的处理有细节,这里只是进行引导,让大家有印象,让计算机专业学生有常识。
下面是使用代码:
# Run agent on the state用状态生成动作
action = mario.act(state)
# Agent performs action动作修改影响环境
next_state, reward, done, info = env.step(action)
# Remember记忆画面,也就是经验
mario.cache(state, next_state, action, reward, done)
# Learn学习
q, loss = mario.learn()
# Logging记录日志
logger.log_step(reward, loss, q)
# Update state更新状态
state = next_state
# Check if end of game判断是否游戏通关。
if done or info["flag_get"]:
break
通过上面的介绍,知道人工智能AI处理电子数据已经很强大成熟了,处理自然数据因为自然数据信息量大,人工智能AI需要的能源太多,暂时不能普及,所以现在科学家和计算机专家在研究标签智能,类似于事务或对象不用每次都分析数据来获得到底是何事务或对象,而是用标签查找或比较来实现,但是这难度非常大,也正在发展中。