
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
这个模块为分析模板准备开始的参数。同时也是程序启动后所见的界面。界面如下:
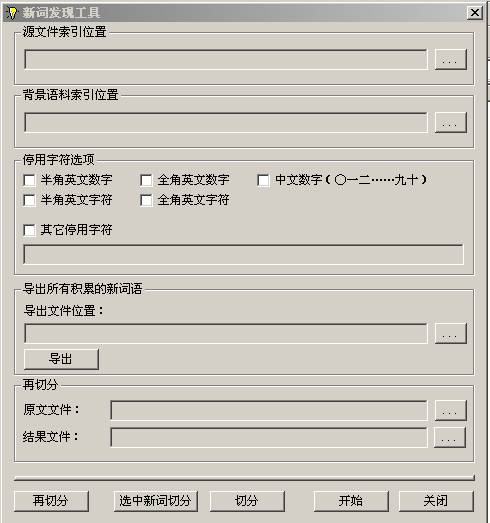
下面是界面上各个部分的使用说明:
源文件索引位置:点击右边的按钮选择一个源文件索引文件。
背景语料索引位置:点击右边的按钮选择一个背景语料索引文件。
停用字符选项:在包括的:半角英文数字、全角英文数字、中文数字、半角英文字符和全角英文字符选项上进行选择,如果还有其它停用字符,在其它停用字符选项上选中,然后在下面的编辑框内输入其它字符。
导出所有积累的新词语:点击右边的按钮选择目标文件,点导出按钮则把系统积累的词库导致到选择的文件上。
再切分:用来控制再切分功能的原文文件和结果文件。点击右边的按钮进行选择。
再切分按钮:点击启动再切分功能。
选中新词切分按钮:在索引文件确定的源文件内容中对重复字串(新词)筛选和结果保存模块确定的选中新词进行切分。
切分按钮:在索引文件确定的源文件内容中对重复字串(新词)筛选和结果保存模块确定的所有新词进行切分。
开始按钮:开始进行重复字串(新词)进行分析。
关闭按钮:关闭程序。
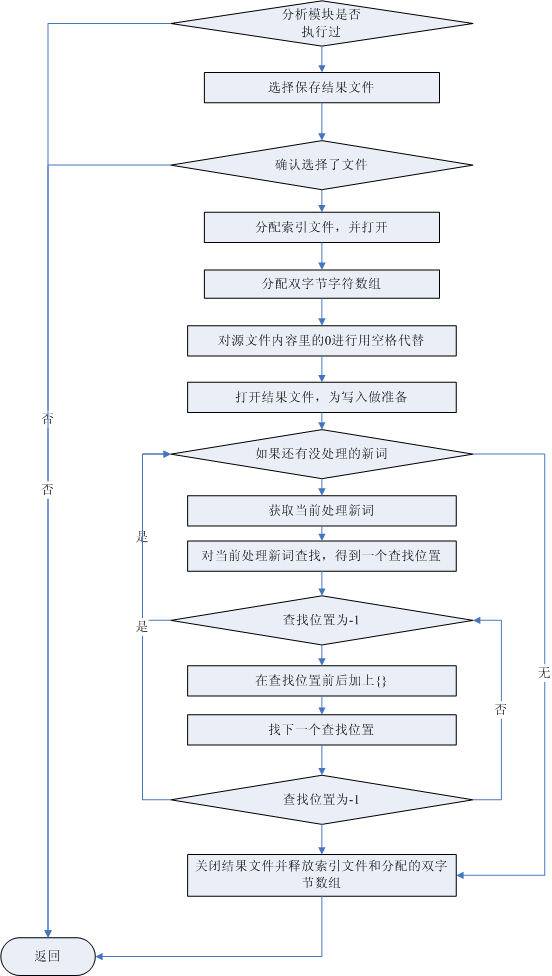
重复字串分析模块是分词处理系统的一个核心,它在源文件索引内容和背景语料索引文件内容基础上,通过后缀PAT array算法,计算出重复字串(新词),下面是它的流程图:
图3 重复字串分析模块流程图

怎样应用算法,把算法以代码描述是一个难点。通过对算法的认真分析,以下面的代码来表达算法。
BOOL CWiseFoundDlg::CalculateLCPRgt(const int *pIndex, const unsigned short *pTxtBuf, int *pLcp, DWORD dwLen)
{
BOOL bSuc = FALSE;
int *pInv = NULL;
__try
{
const unsigned short *s = pTxtBuf;
pInv = (int *)VirtualAlloc(NULL, dwLen*sizeof(int), MEM_RESERVE|MEM_COMMIT, PAGE_READWRITE);
if (NULL == pInv) __leave;
for(DWORD i = 0; i < dwLen; i++) pInv[pIndex[i]] = i;
int h = 0;
for(i = 0; i < dwLen; i++)
{
int x = pInv[i];
int j = pIndex[x+1];
for(const unsigned short *p1 = s+i+h, *p0 = s+j+h; (*p1 == *p0) && *p1; p1++, p0++, h++);
pLcp[x] = h;
if(h > 0 h--;
}
bSuc = TRUE;
}
__finally
{
if (pInv VirtualFree(pInv, dwLen*sizeof(int), MEM_RELEASE);
return bSuc;
}
}
BOOL CWiseFoundDlg::CalculateLCPLft(const int *pIndex, const unsigned short *pTxtBuf, int *pLcp, DWORD dwLen)
{
BOOL bSuc = FALSE;
int *pInv = NULL;
__try
{
const unsigned short *s = pTxtBuf;
pInv = (int *)VirtualAlloc(NULL, dwLen*sizeof(int), MEM_RESERVE|MEM_COMMIT, PAGE_READWRITE);
if (NULL == pInv) __leave;
for(DWORD i=0; i<dwLen; i pInv[pIndex[i]] = i;
int h = 0;
for(i = dwLen-1;; i--)
{
int x = pInv[i];
int j = pIndex[x+1];
for(const unsigned short *p1 = s+i-h, *p0 = s+j-h; (*p1 == *p0) && *p1; p1--, p0--, h++);
pLcp[x] = h;
if(h > 0 h--;
if (0 == i)? break;
}
bSuc = TRUE;
}
__finally
{
if (pInv VirtualFree(pInv, dwLen*sizeof(int), MEM_RELEASE);
return bSuc;
}
}
重复字串(新词)筛选和结果保存模块使用原始的由重复字串分析模块分析出来的重复字串,并保存了筛选结果,同时使分析出来的结果可以保存到系统词库内。
这个模块的界面如下:
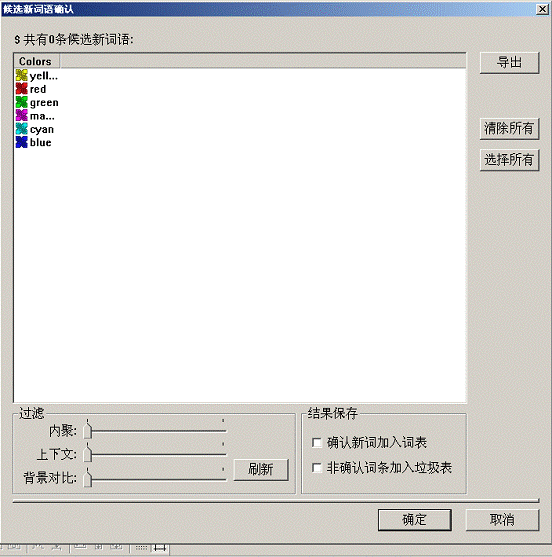
界面上元素功能如下:
过滤框内的内聚、上下文和背景对比参数能够过滤分析模块生成的结果项,把不满足条件的重复字串排除掉。
选中“确认新词加入词表”则会通知分析模块在退出时把上面的ListCtrl里选中的词表加入到系统的词库里。
选中“非确认词条加入垃圾表”则会通知分析模块在退出时把上面的ListCtrl里未选中的项目加入到系统的垃圾词库里。
清除所有,会使所有显示的重复字串(新词)为未选中状态。
选择所有,会使所有显示的重复字串(新词)为选中状态。
点击确定时,关闭窗口并返回给上层确定状态。取消则返回取消状态。
点击导出按钮,则把显示的重复字串(新词)导出到文件里。
对于分析出来的重复字串(新词)还按照内聚、上下文、背景对比进行了过滤。
基于新词的切分模块,它对重复字串分析模块分析出来的所有重复字串(新词)在源文件内进行查找和切分,并生成切分结果文件。
对于双字节字符的理解是本模块的难点。汉字是双字节字符,在处理里必须要用WCHAR这类双字节字符数组来进行保存,用WCHAR保存过后,再转到CString变量里,就可以容易地进行查找和插入了。
这个模块和上个模块的处理流程类似,只不过只对界面上选中的重复字串(新词)进行切分。
用户界面采用Web的方式提供给用户,这需要一个Web服务器包,用以提供Web服务,代码是由c程序完成,在程序中指定服务端口和服务名。用户可以在浏览器中以http://主机名:端口/服务名的方式来访问。用户网页提供一个输入框和搜索按钮,共用户输入需求并检索,检索结果显示在输入框下面,如果结果较多将分页显示,结果显示出按接近用户需求排序中文或英文文档的集合以及他们的译文。因为语料中每一个文档很小,所以可以全部显示他们。