
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
PAT-Array(又称为Suffix Array)是在信息检索领域被成功使用的一种十分有效的数据结构。(1)、创建PAT-Array。
Suffix array
LCP arrays on both sides
图1 PAT-Array示例
图2 实际文本(小说《笑傲江湖》片断)PAT-Array的可视化表示 |
整个论文分为六个部分,绪论介绍分词处理技术相关的背景和基础知识以及这次论文的目标,后面各章节全部围绕系统的设计的各个细节来描述。分别为
第2章 信息系统的系统分析,包括用户的各种需求和系统的各个结构,预先估计系统设计可能会遇到的困难,为设计系统构架,组织模块打好基础。
第3章 系统模块设计与分析,把系统分为几个大的功能模块,想清楚模块之间的关系,资源的从属关。尽量避免模块间的功能重叠或混乱。
第4章 这一章将详细描述各个模块的设计方法,将模块化为更小的功能块,阐述各个功能块的作用,各种数据结构设计的合理性和优越性。说明个系统模块的性能。
第5章 分析整体系统难点,缺陷以及没有解决的问题,已经对系统以后改进发展的看法。
第6章 对这次设计中各种性能优化,整体结构设计的经验进行总结。
无词典分词是指不依靠词典把文章中的词提取出来, 词是汉字字符的一个结合模式, 但并不是每种结合模式都构成词, 只有那些具有确定语义或语法功能的汉字结合模式才是词, 而在不使用词典的情况下, 由于缺乏先验知识, 词是无法直接识别的. 但在统计意义上, 每个文档中的汉字结合模式是可以观察的. 如果一个词在一篇文档中重复出现的次数越多, 则这个词就越容易被识别出来, 反之,这个词在文档中只出现一次或很少出现, 则不易被识别. 无词典分词算法的主要思想就是利用汉字的结合模式在文档中重复出现的次数来判断这个结合模式是否是一个词. 而这种分词方法完全不依赖于词典, 因此称为无词典分词.
分词的目标是尽可能把文档中出现的词找出来, 词的识别精度也要尽可能高.
首先, 读入一篇文档, 把整篇文档存入一个字符串str 中. 根据此字符串生成一个后缀数组int S [ ]以及最长公共前缀信息数组int LCP[ ] . 后缀数组长度为字符串的长度, 最长公共前缀的长度为字符串str 的长度+ 1. 同时也得到后缀数组的最长公共前缀信息.
第二步, 存放汉字的结合模式。
第三步, 对存放中的汉字串(候选词) 进行处理和筛选, 最终得到的结果就是抽到的词.
最后, 利用前三步得到的是“词”对文档进行切分, 并把抽到的词和切分的结果存到文件中。并提供对选中新词进行切分和再切分功能。
对性能要求首先要保证的就是稳定性,对于执行算法时间长的程序,要减少一切可能崩溃的可能。必须消除所有的内存泄漏。减少线程处理可能产生的错误,保障系统稳定运行。
另外一定要保证较高的查询速度,由于数据量可能非常大,导致索引量非常大。
这次分词处理系统的主要构架有六个部分组成,包括重复字串分析参数准备模块、重复字串分析模块、重复字串(新词)筛选和结果保存模块、基于新词的切分模块、基于选中新词的切分模块和再切分模块。(见图1)
图1 分词处理系统总体构架
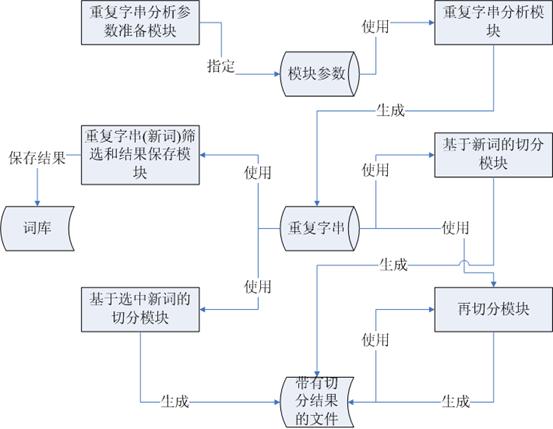
重复字串分析参数准备模块:负责指定源文件索引文件位置、背景语料索引位置和停用字符集合。
重复字串分析模块:根据源文件索引和背景语料索引进行分析,生成重复字串。
重复字串(新词)筛选和结果保存模块:提供界面让用户可以筛选重复字串,并且保存筛选的结果,以供基于选中新词的切分模块使用,同时提供功能让重复字串(新词)保存到系统词库里。
基于新词的切分模块:对重复字串分析模块分析出来的所有重复字串(新词)在源文件内进行查找和切分,并生成切分结果文件。
基于选中新词的切分模块:对重复字串(新词)筛选和结果保存模块筛选出来的重复字串(新词)在源文件内进行查找和切分,并生成切分结果文件。
再切分模块:对重复字串(新词)筛选和结果保存模块筛选出来的重复字串(新词)在对于上面两个切分模块生成的文件内进行再次查找切分,并生成切分结果文件。
在图1已经用箭头表示出了这个分词处理系统中数据的流动方向。
重复字串分析参数准备模块,它负责指定源文件索引文件位置、背景语料索引位置和停用字符集合。而这些数据是重复字串分析模块所需要的。
重复字串分析模块依赖于模块参数生成了重复字串。
重复字串(新词)筛选和结果保存模块使用原始的由重复字串分析模块分析出来的重复字串,并保存了筛选结果,同时使分析出来的结果可以保存到系统词库内。
基于新词的切分模块,它对重复字串分析模块分析出来的所有重复字串(新词)在源文件内进行查找和切分,并生成切分结果文件。
基于选中新词的切分模块,它对重复字串(新词)筛选和结果保存模块筛选出来的重复字串(新词)在源文件内进行查找和切分,并生成切分结果文件。
再切分模块,它对重复字串(新词)筛选和结果保存模块筛选出来的重复字串(新词)在对于上面两个切分模块生成的文件内进行再次查找切分,并生成切分结果文件。
