
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
Basic concepts of speech recognition
Speech is a complex phenomenon. People rarely understand how is it produced and perceived. The naive perception is often that speech is built with words and each word consists of phones. The reality is unfortunately very different. Speech is a dynamic process without clearly distinguished parts. It’s always useful to get a sound editor and look into the recording of the speech and listen to it. Here is for example the speech recording in an audio editor. 言语是一种复杂的现象。人们很少理解它是如何产生和感知的。天真的感觉通常是语音是用文字构建的,每个单词都由发声组成。不幸的是,现实情况非常不同。言语是一个没有明确区分的动态过程。获得一个声音编辑器并查看语音录音并听取它总是有用的。这是例如音频编辑器中的语音记录。
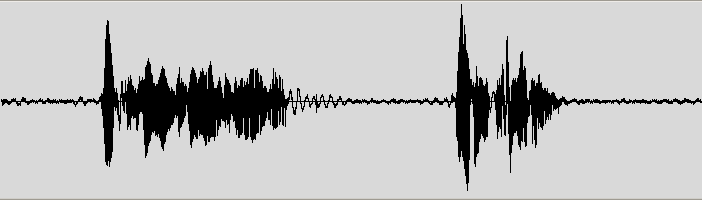
All modern descriptions of speech are to some degree probabilistic. That means that there are no certain boundaries between units, or between words. Speech to text translation and other applications of speech are never 100% correct. That idea is rather unusual for software developers, who usually work with deterministic systems. And it creates a lot of issues specific only to speech technology. 所有现代语言描述在某种程度上都是概率性的。这意味着单位之间或单词之间没有特定的界限。言语到文本翻译和其他语音应用永远不会100%正确。对于通常使用确定性系统的软件开发人员来说,这个想法是不寻常的。它创造了许多仅针对语音技术的问题。
Structure of speech
In current practice, speech structure is understood as follows: 在目前的实践中,语音结构理解如下:
Speech is a continuous audio stream where rather stable states mix with dynamically changed states. In this sequence of states, one can define more or less similar classes of sounds, or phones. Words are understood to be built of phones, but this is certainly not true. The acoustic properties of a waveform corresponding to a phone can vary greatly depending on many factors - phone context, speaker, style of speech and so on. The so-called coarticulation makes phones sound very different from their “canonical” representation. Next, since transitions between words are more informative than stable regions, developers often talk about diphones - parts of phones between two consecutive phones. Sometimes developers talk about subphonetic units - different substates of a phone. Often three or more regions of a different nature can be found. 语音是连续的音频流,其中相当稳定的状态与动态改变的状态混合。在这种状态序列中,可以定义或多或少相似类别的声音或发声。言语被理解为由发声构成,但这当然不是真的。对应于发声的波形的声学特性可以根据许多因素而变化很大 - 发声环境,扬声器,语音风格等。所谓的衔接使得发声听起来与他们的“规范”表现非常不同。接下来,由于单词之间的转换比稳定区域更具信息性,开发人员经常谈论双音素 - 两部连续发声之间的部分发声。有时开发人员会谈论语音单位 - 发声的不同子状态。通常可以找到三个或更多不同性质的区域。
The number three can easily be explained: The first part of the phone depends on its preceding phone, the middle part is stable and the next part depends on the subsequent phone. That’s why there are often three states in a phone selected for speech recognition. 第三个可以轻松解释:发声的第一部分取决于其前面的发声,中间部分是稳定的,下一部分取决于后续发声。这就是选择用于语音识别的发声中通常有三种状态的原因。
Sometimes phones are considered in context. Such phones in context are called triphones or even quinphones. For example “u” with left phone “b” and right phone “d” in the word “bad” sounds a bit different than the same phone “u” with left phone “b” and right phone “n” in word “ban”. Please note that unlike diphones, they are matched with the same range in waveform as just phones. They just differ by name because they describe slightly different sounds. 有时发声被视为上下文。上下文中的这类发声被称为三音发声 甚至是qu发声。例如在单词“bad”里“u”与左发声“b”和右发声“d” 有点不同于在单词“ban”里的“u”与左发声“b”和右发声“n”情况下的发声 。请注意,与双音素不同,它们的波形范围与发声相同。它们只是名称不同,因为它们描述的声音略有不同。
For computational purpose it is helpful to detect parts of triphones instead of triphones as a whole, for example if you want to create a detector for the beginning of a triphone and share it across many triphones. The whole variety of sound detectors can be represented by a small amount of distinct short sound detectors. Usually we use 4000 distinct short sound detectors to compose detectors for triphones. We call those detectors senones. A senone’s dependence on context can be more complex than just the left and right context. It can be a rather complex function defined by a decision tree, or in some other ways. 出于计算目的,检测三音素的部分而不是整个三音素是有帮助的,例如,如果你想为三音素的开头创建一个探测器并在很多三音素发声中共享它。各种声音探测器可由少量不同的短声音探测器表示。通常我们使用4000个不同的短声音探测器来组成三音素探测器。我们将这些探测器称为senones。Senone对上下文的依赖可能比左右上下文更复杂。它可以是由决策树或其他方式定义的相当复杂的函数。
Next, phones build subword units, like syllables. Sometimes, syllables are defined as “reduction-stable entities”. For instance, when speech becomes fast, phones often change, but syllables remain the same. Also, syllables are related to an intonational contour. There are other ways to build subwords - morphologically-based (in morphology-rich languages) or phonetically-based. Subwords are often used in open vocabulary speech recognition. 接下来,发声构建子词单元,如音节。有时,音节被定义为“减少稳定的实体”。例如,当语音变快时,发声经常会改变,但音节保持不变。另外,音节与语调轮廓有关。还有其他方法来构建子词 - 基于形态学(在形态丰富的语言中)或基于语音的。子词通常用于开放词汇量语音识别。
Subwords form words. Words are important in speech recognition because they restrict combinations of phones significantly. If there are 40 phones and an average word has 7 phones, there must be 40^7 words. Luckily, even people with a rich vocabulary rarely use more then 20k words in practice, which makes recognition way more feasible. 子词形成单词。单词在语音识别中很重要,因为它们极大地限制了发声的组合。如果有40部发声,平均每个单词有7部发声,则必须有40 ^ 7个单词。幸运的是,即使是词汇丰富的人在实践中也很少使用超过20k的单词,这使得识别方式更加可行。
Words and other non-linguistic sounds, which we call fillers (breath, um, uh, cough), form utterances. They are separate chunks of audio between pauses. They don’t necessary match sentences, which are more semantic concepts. 单词和其他非语言的声音,我们称之为填充物(呼吸,嗯,呃,咳嗽),形成话语。它们是暂停之间单独的音频块。它们不需要匹配句子,这是更多的语义概念。
On the top of this, there are dialog acts like turns, but they go beyond the purpose of this document. 最重要的是,有像转弯一样的对话行为,但它们超出了本文档的目的。
Recognition process
The common way to recognize speech is the following: we take a waveform, split it at utterances by silences and then try to recognize what’s being said in each utterance. To do that, we want to take all possible combinations of words and try to match them with the audio. We choose the best matching combination. 识别语音的常用方法如下:我们采用波形,通过静音将其分解为话语,然后尝试识别每个话语中的内容。为此,我们希望采用所有可能的单词组合,并尝试将它们与音频匹配。我们选择最佳匹配组合。
There are some important concepts in this matching process. First of all it’s the concept of features. Since the number of parameters is large, we are trying to optimize it. Numbers that are calculated from speech usually by dividing the speech into frames. Then for each frame, typically of 10 milliseconds length, we extract 39 numbers that represent the speech. That’s called a feature vector. The way to generate the number of parameters is a subject of active investigation, but in a simple case it’s a derivative from the spectrum. 这个匹配过程中有一些重要的概念。首先,它是功能的概念。由于参数的数量很大,我们正在尝试对其进行优化。从语音计算的数字一般是通过将语音划分为帧。然后,对于每帧,通常为10毫秒长度,我们提取39个代表语音的数字。这被称为特征向量。生成参数数量的方法是一个积极调查的主题,但在一个简单的情况下,它是光谱的衍生物。
Second, it’s the concept of the model. A model describes some mathematical object that gathers common attributes of the spoken word. In practice, for an audio model of senone it is the gaussian mixture of it’s three states - to put it simple, it’s the most probable feature vector. From the concept of the model the following issues raise: 其次,它是模型的概念。模型描述了一些收集说出的单词的共同属性的数学对象。在实践中,对于Senone的音频模型来说,它是三种状态的高斯混合 - 简单来说,它是最可能的特征向量。从模型的概念出发,提出了以下问题:
The model of speech is called Hidden Markov Model or HMM. It’s a generic model that describes a black-box communication channel. In this model process is described as a sequence of states which change each other with a certain probability. This model is intended to describe any sequential process like speech. HMMs have been proven to be really practical for speech decoding. 语音模型称为隐马尔可夫模型或HMM。它是描述黑盒通信通道的通用模型。在该模型中,过程被描述为以一定概率彼此改变的状态序列。此模型旨在描述任何顺序过程,如语音。HMM已被证明对语音解码非常实用。
Third, it’s a matching process itself. Since it would take longer than universe existed to compare all feature vectors with all models, the search is often optimized by applying many tricks. At any points we maintain the best matching variants and extend them as time goes on, producing the best matching variants for the next frame. 第三,它本身就是一个匹配过程。由于将所有特征向量与所有模型进行比较需要比宇宙存在更长的时间,因此通常通过应用许多技巧来优化搜索。在任何时候,我们都会保持最佳匹配变体,并随着时间的推移扩展它们,为下一帧产生最佳匹配变体。
Models模型
发音到文本的映射,语言学字符预测。
According to the speech structure, three models are used in speech recognition to do the match: 根据语音结构,语音识别中使用三种模型进行匹配:
An acoustic model contains acoustic properties for each senone. There are context-independent models that contain properties (the most probable feature vectors for each phone) and context-dependent ones (built from senones with context). 一个声学模型包含每个句音声学特性。上下文无关的模型包含属性(每个发声最可能的特征向量)和依赖于上下文的属性(从带有上下文的senones构建)。
A phonetic dictionary contains a mapping from words to phones. This mapping is not very effective. For example, only two to three pronunciation variants are noted in it. However, it’s practical enough most of the time. The dictionary is not the only method for mapping words to phones. You could also use some complex function learned with a machine learning algorithm. 一个语音字典包含话发声的映射。这种映射不是很有效。例如,其中仅注意到两到三个发音变体。但是,大部分时间它都很实用。字典不是将单词映射到发声的唯一方法。您还可以使用通过机器学习算法学习的一些复杂函数。
A language model is used to restrict word search. It defines which word could follow previously recognized words (remember that matching is a sequential process) and helps to significantly restrict the matching process by stripping words that are not probable. The most common language models are n-gram language models–these contain statistics of word sequences–and finite state language models–these define speech sequences by finite state automation, sometimes with weights. To reach a good accuracy rate, your language model must be very successful in search space restriction. This means it should be very good at predicting the next word. A language model usually restricts the vocabulary that is considered to the words it contains. That’s an issue for name recognition. To deal with this, a language model can contain smaller chunks like subwords or even phones. Please note that the search space restriction in this case is usually worse and the corresponding recognition accuracies are lower than with a word-based language model. 一个语言模型用于限制单词搜索。它定义哪个单词可以跟随先前识别的单词(记住匹配是一个顺序过程),并通过剥离不可能的单词来帮助显着限制匹配过程。最常见的语言模型是n-gram语言模型 - 这些模型包含单词序列和有限状态语言模型的统计 - 这些模型通过有限状态自动化定义语音序列,有时使用权重。要达到良好的准确率,您的语言模型必须在搜索空间限制方面非常成功。这意味着它应该非常善于预测下一个单词。语言模型通常会限制考虑其包含的单词的词汇。这是名称识别的问题。为了解决这个问题,语言模型可以包含较小的块,如子词甚至发声。
Those three entities are combined together in an engine to recognize speech. If you are going to apply your engine for some other language, you need to get such structures in place. For many languages there are acoustic models, phonetic dictionaries and even large vocabulary language models available for download. 这三个实体在引擎中组合在一起以识别语音。如果您要将引擎应用于其他语言,则需要使用此类结构。对于许多语言,可以下载声学模型,语音词典甚至大词汇量语言模型。
Other used concepts
A Lattice is a directed graph that represents variants of the recognition. Often, getting the best match is not practical. In that case, lattices are good intermediate formats to represent the recognition result.
N-best lists of variants are like lattices, though their representations are not as dense as the lattice ones.
甲格子是一个有向图,表示识别的变体。通常,获得最佳匹配是不切实际的。在这种情况下,格子是表示识别结果的良好中间格式。
N个最佳变体列表就像格子一样,尽管它们的表示不像格点那样密集。
Word confusion networks (sausages) are lattices where the strict order of nodes is taken from lattice edges. 单词混淆网络(香肠)是格子,其中节点的严格顺序取自格子边缘。
Speech database - a set of typical recordings from the task database. If we develop dialog system it might be dialogs recorded from users. For dictation system it might be reading recordings. Speech databases are used to train, tune and test the decoding systems. 语音数据库 - 来自任务数据库的一组典型记录。如果我们开发对话系统,它可能是用户记录的对话框。对于听写系统,它可能正在阅读录音。语音数据库用于训练,调整和测试解码系统。
Text databases - sample texts collected for e.g. language model training. Usually, databases of texts are collected in sample text form. The issue with such a collection is to put present documents (like PDFs, web pages, scans) into a spoken text form. That is, you need to remove tags and headings, to expand numbers to their spoken form and to expand abbreviations. 文本数据库 - 为例如语言模型培训收集的示例文本。通常,文本数据库以样本文本形式收集。这种集合的问题是将当前文档(如PDF,网页,扫描)放入口头文本表格中。也就是说,您需要删除标签和标题,将数字扩展为其口头形式并扩展缩写。
What is optimized
When speech recognition is being developed, the most complex problem is to make search precise (consider as many variants to match as possible) and to make it fast enough to not run for ages. Since models aren’t perfect, another challenge is to make the model match the speech. 在开发语音识别时,最复杂的问题是使搜索精确(考虑尽可能多的变体匹配)并使其足够快以至于不能运行多年。由于模型并不完美,另一个挑战是使模型与语音匹配。
Usually the system is tested on a test database that is meant to represent the target task correctly. 通常,系统在测试数据库上进行测试,该数据库旨在正确表示目标任务。
The following characteristics are used:
Word error rate. Let’s assume we have an original text and a recognition text with a length of Nwords. I is the number of inserted words, D is the number of deleted words and S represent the number of substituted words. With this, the word error rate can be calculated as使用以下特征:
字错误率。假设我们有一个原始文本和一个长度为N个单词的识别文本。I是插入单词的数量, D是删除单词的数量,S表示替换单词的数量。这样,单词错误率可以计算为
WER = (I + D + S) / N
The WER is usually measured in percent. WER =(I + D + S)/ N.
WER通常以百分比来衡量。
Accuracy. It is almost the same as the word error rate, but it doesn’t take insertions into account. 准确性。它与单词错误率几乎相同,但不考虑插入。
Accuracy = (N - D - S) / N精度=(N - D - S)/ N.
For most tasks, the accuracy is a worse measure than the WER, since insertions are also important in the final results. However, for some tasks, the accuracy is a reasonable measure of the decoder performance. 对于大多数任务而言,准确度是比WER更差的度量,因为插入在最终结果中也很重要。但是,对于某些任务,精度是解码器性能的合理度量。
Speed. Suppose an audio file has a recording time (RT) of 2 hours and the decoding took 6 hours. Then the speed is counted as 3xRT. 速度。假设音频文件的录制时间(RT)为2小时,解码时间为6小时。然后速度计为3xRT。
ROC curves. When we talk about detection tasks, there are false alarms and hits/misses. To illustrate these, ROC curves are used. Such a curve is a diagram that describes the number of false alarms versus the number of hits. It tries to find the optimal point where the number of false alarms is small and the number of hits matches 100%.
There are other properties that aren’t often taken into account, but still important for many practical applications. Your first task should be to build such a measure and systematically apply it during the system development. Your second task is to collect the test database and test how your application performs.
ROC曲线。当我们谈论检测任务时,会出现误报和命中/未命中。为了说明这些,使用ROC曲线。这样的曲线是描述错误警报的数量与命中数量的图表。它试图找到错误警报数量较少且命中数量达到100%的最佳点。
还有其他一些属性不经常被考虑在内,但对许多实际应用仍然很重要。您的首要任务应该是构建这样的度量并在系统开发过程中系统地应用它。您的第二个任务是收集测试数据库并测试应用程序的执行方式。
在开始之前
要构建一个语音字典,您可以使用现有的TTS合成器之一,它现在涵盖了很多语言。您也可以手动提升字典,然后使用机器学习工具进行扩展。
对于语言模型,您必须为您的域找到大量文本。它可能是教科书,已经转录的录音或其他来源,如在网络上抓取的网站内容。
如果我们谈论的是大型词汇解码器,必须有一个二元化框架,一个适应框架和一个后处理框架。他们都需要以某种方式合作。sphinx4的灵活性允许您快速构建这样的系统。将sphinx4嵌入像red5这样的flash服务器很容易,可以提供基于Web的识别。管理在群集上进行大规模解码的许多sphinx4实例很容易。
另一方面,如果您的系统需要高效且合理准确,如果您在嵌入式设备上运行,或者如果您有兴趣使用具有Erlang等异域语言的识别器,那么pocketphinx就是您的选择。将Java与JVM不支持的其他语言集成起来非常困难 - 在这种情况下,pocketsphinx更好。
最后,您需要选择开发平台。如果你受某个特定的约束,这对你来说是一件容易的事。如果您可以选择,我们强烈建议您使用GNU / Linux作为开发平台。我们可以帮助您解决Windows或Mac问题,但无法保证 - 我们的主要开发平台是Linux。对于许多任务,您需要使用Perl或Python运行复杂的脚本。在Windows上,它可能会有问题。
麦克风识别英语
bin\Release\Win32\pocketsphinx_continuous.exe -inmic yes
-hmm model\en-us\en-us -lm model\en-us\en-us.lm.bin
-dict model\en-us\cmudict-en-us.dict
识别文件
bin\Release\Win32\pocketsphinx_continuous.exe -infile test\data\goforward.raw
-hmm model\en-us\en-us -lm model\en-us\en-us.lm.bin
-dict model\en-us\cmudict-en-us.dict
Pocketsphinx API旨在简化应用程序中语音识别器功能的使用:
有关新API的参考文档,请访问https://cmusphinx.github.io/doc/pocketsphinx/。