
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
我们考虑下面这个AIMD速率控制算法的原型:
在每一次速率控制的间隔,如果没有从接收端得到负反馈(丢包,渐增的延迟等),而 是得到正反馈(ACK),那么发包的速率(x)将增加α(x)。
x ← x + α(x) (1)
α(x)是一个非增的曲线,并且它随着x递增趋近于0。即:
limx → + ∞α(x) = 0

上图描述了α(x)的曲线,并和TCP NewReno版本的AIMD的算法曲线做了图示比较。
对于任意的负反馈(NAK),发送速率按一个常量因子β(0 < β <1)进行降低:
x ← (1 - β)·x (2)
注意,公式(1)以基于一个固定的控制间隔:RTT。它不同于TCP的控制(每一个应答触 发一次递增)。
通过修改α(x),可以确定一个在UDT中使用的速率控制算法类:DAIMD算法(AIMD with decreasing increases),即加性的参数是递减的。
除了稳定性和公平性,函数α(x)在x=0值附近,值极大用以提高效率;并且能快速地降 低,用以降低震荡。
UDT采取该高效的方法,并且指定一个分段的与链路容量相关的α(x)。UDT固定的速 率控制间隔是SYN(或称为同步时间间隔),并且SYN值是0.01秒。UDT的速率控制是一 个通过指定α(x)的特别的DAIMD算法:
α(x) = 10[log(L-C(X))]-τ × 1500/S · 1/SYN (3)
在公式(3)里:
x的单位是:包数/秒。
L是链路容量,并且单位是:bits/秒。
S是UDT包大小(指IP的有效负荷),以字节统计。
C(x)是一个单位转换函数(C(x) = x * S * 8),将当前的发送速率x从包数/秒转换成 bits/秒。
τ是一个协议参数,在当前协议规范里指定的值是9.
因子1500 / S用来平衡不同包大小的流产生的影响。UDT将一个标准包大小处理为 1500字节。
当第一个NAK包被接收或者流量窗口到达最大大小时,上面描述的UDT拥塞控制就变 的不适用。UDT使用了慢启动阶段的拥塞控制。在该阶段里,包之间的时间保持为0。初始的 流量窗口大小是2,并且每触发一次ACK事件时,窗口流量大小被设置为应答包的数量。慢 启动只发生在UDT建立连接后的初期。一旦进入上述的拥塞控制方法(DAIMD)阶段,慢启 动将不会再出现。
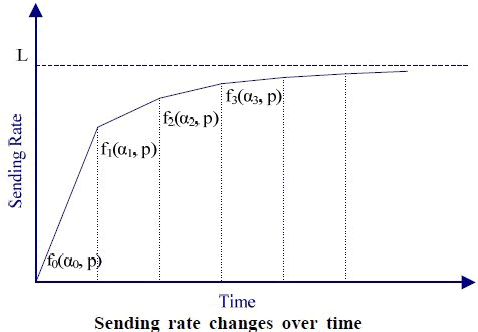
上图显示了,单一的UDT流如何随时间,改变其发送速率。该情形的前提是:网络系统 里既没有非拥塞控制的丢包,也没有其它的流。否则将会出现发送速率的震荡。
上图里,在每一个阶段k(k = 0,1,2…),当x在0附近或者增长和降低相互抵消时, 它可以达到平衡。发送速率在不同阶段k,近似的平衡值:
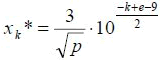 (4)
(4)
变量p是丢包速率。
变量e 是一个值,满足:
许多UDT的特性可以通过公式(4)进一步推演。一个有趣的例子是TCP的友好性。通过和 简单版本的TCP吞吐量的模型[5]做比较(4),可以得到一个充分条件,用以保证UDT不 如TCP那般激进:
 (5)
(5)
条件(5)显示了,在低速的BDP环境里,UDT对于TCP是非常友好的。另外,RTT对TCP 友好性的影响超过了带宽。
UDT使用基于接收端的包对(package pairs),用来估计链路容量L。UDT发送端每隔 16个数据包,发出一个包对(忽略包之间的等待时间)。也可以使用其它方式的包对或者长队, 因为在接收端,可以通过包的时间标签信息,判断这些接收到的包是否由一个包对或者长 队构成。
接收端记录包对或者长队的每一个原子包的到达时间,然后对这些值使用中值过滤, 用来计算链路容量。假设中值时间是T,该测量周期里的平均包大小是S,那么链路容量可 以被估计为 S / T。
在使用包对估计链路容量时,有两个重要的关注点。一个是交叉航路的影响。交叉航路的 存在可能造成对容量的低估。另一个关注点是,网络接口卡的中断结合。高速的网卡通常都 有中断结合(interrupt coalescence)的功能,用来避免频繁的中断。这样可以使多个 包到达后,仅仅通过一次中断通知上层处理。因此,链路容量可能被高估了。这种问题,可 以通过使用多个包对到达的平均时间来消除。
然而,在大部分情况下,估计错误是不可避免的。当网络只有一个流时,UDT可能高估 容量。当存在多个流时,UDT可能低估容量。对于一个流,容量估计错误只会影响到收敛时 间。对于多个流时,估计错误也可能影响到公平性(注意,如果所有的流都被估计成相同的 错误,它们仍然可以达到公平性)。
在UDT的增长公式(3)里使用上限函数的一个重要的理由是,减少估计错误的影响。如同 一个直观的例子,如果2个流共享一个100Mb/s的链路,流1测量的链路容量是 101Mb/s,流2测量的链路容量是99Mb/s,于是2个流仍然几乎相等地共享着带宽。当流1 超过1Mb/s时,它会和流2一样进入相同的阶段,并且两个流将出现相同的增长和降低。
虽然大多数基于丢包的拥塞控制在工作,包丢失被认为是一个简单的拥塞指示,但是 这些控制很少在真实的网络环境里对包丢失的模式做过研究。因为一个包丢失可能造成乘性 地速率的降低,所以包丢失处理显得非常重要。
有3类涉及到包丢失的特别情形,需要被解决。
1,失去同步。
2,非拥塞的包丢失。
3,包的重新排序。
失去同步是一个条件。当所有的并发流几乎在同一时间发生丢包时,即失去同步。非拥 塞的包丢失通常因为出现了链路错误导致,并且该非拥塞的包丢失可能会向传输协议发出 错误的网络拥塞信号。另外,包的再排序可以误导接收端将其作为丢失包处理。
因为已经有高效的方法来解决包再排序的问题,所以本节的焦点落在前2种情形上, 并且在该情形在文献里的方法不适用于UDT。
失去同步这种现象是一个情形:当所有并发流同时增加和减少它们的发包速率时,这 时,总计吞吐量产生非常大的震荡,并且导致带宽总计利用率降低。现象的本质原因是:当 拥塞发生时,几乎所有的流会发现丢包,然后不得不放弃它们的发送;当没有拥塞发生时, 它们都增加发包速率。
UDT使用一种随机取样的方法来缓解这个问题。为了描述这个方法,定义3个术语:
1,丢失事件(Loss event):当包丢失被检测到时触发丢失事件。当发送端接收到 一个NAK控制包时,UDT发送端可以检测一个丢失事件。
2,拥塞事件(Congestion event):是一个特殊的丢失事件。当最后一次速率降低 发生时,在丢失事件里丢失的包中的最大序列号,要大于已经发送的包里最大的 序列号时,触发该事件。
3,拥塞周期(Congestion Period):两个持续的拥塞事件的间隔时间称为拥塞周 期。
假设当前有M个丢失事件发生时间夹在两个拥塞事件之间,并且N是在1和M之间满足 均匀分布的随机数。
每一个拥塞周期里,UDT控制算法的降低因子是在[1/9,1 – (8/9)N]范围内的 随机数。一旦一个NAK控制包被接收,如果这个NAK包开启了一个新的拥塞周期, 即该事件就是拥塞事件,发包周期增加1 / 8(和降低发送速率1/9相等),并且在下 一个SYN时间间隔点停止发包。每隔N个丢失事件,发包周期将进一步增加另一个 1 / 8。
注意,UDT的明确的丢失报告(NAK)的用处和TCP的重复ACK的用处不同。通过重复地 ACK响应,TCP的发送端在一个拥塞事件里,可能不知道所有的丢失事件,并且通常只检 测第一个丢失事件。事实上,大部分TCP的实现在每一个RTT,不止一次地不降低发送速率。
但是,在UDT,所有的丢失事件,通过NAK包来通知。
如果有大量的非拥塞造成的包丢失(比如链路错误,设备故障等),基于丢包(Lossbased) 的控制算法可能工作的不理想。因为它们认为所有丢失的包归因于网络拥塞,于是 就降低数据发送速率。虽然在光纤链路上,产生链路错误的几率非常低,但是这些包丢失归 因于设备故障和错误的设备参数配置。
UDT使用一个简单的机制,用来容忍这类问题。
在噪声链路上,UDT不在一次拥塞事件里,对第一个丢失包做处理。然而,如果在一 次拥塞事件里,有多余一个的丢失包时,将降低发包速率。这种方法,在非拥塞丢失包出现 概率小的网络里,是非常有效的。毫无疑问,它也适用于轻量的包重新排序的问题。

在上面的图片里,每一个点表示为一个丢失事件,红色的点表示在一个拥塞周期里第 一个丢失事件(在一个拥塞周期里,可以出现多个丢失事件)。
假设在一个拥塞周期里丢失事件数量是M,那么UDT在1和M之间选择一个随机数N。
那么每N个包,发送速率减少1 / 9(即AIMD的β因子)。
UDT定义了4大类可配置特性,用来支持拥塞控制的可配置机制。
1,控制事件句柄的回调。
2,协议行为的配置。
3,包结构的扩展。
4,性能监控。
在基类CCC里,定义了7个简单的回调函数。当一个控制事件被触发时,这些回调函数 被调用。
Init和close:这两个方法在UDT建立连接和关闭连接时被回调。它们用于初始化和释 放必要的数据结构。
onACK:当一个ACK控制包在接收端被接收时,该函数被回调。应答的包序列号可以 从该函数的输入参数获取。
onLoss:当发送端检测到一个包丢失事件时,该函数被回调。确定的丢包信息作为 onLoss的接口参数传给用户。注意,该函数可能是多余的:大多数TCP算法 仅重复发送ACK包来检测丢包。
onTimeout:一个超时事件可以触发回调该函数。用户可以指定超时值,否则,使用 默认超时值。
onPktSent:在一个数据包被发送之前,该函数被回调。这个将要被发送的包信息 (序列号,时间标签,大小等)可以通过该函数的输入参数获取。
onPktReceived:在一个数据包被接收后,该函数被回调。和onPktSent相似,这 个包信息可以让用户通过该函数的参数访问。
onPktSent和onPktReceived函数是两个功能非常强大的回调函数, 因为它们允许用户检查每一个数据包。例如,onPktReceived函数可 以被重新定义,用以在TFRC中计算丢包速率。基于相同的原因,这两 个回调函数也可以允许用户追踪协议的微观行为。
processCustomMsg:该回调函数用于处理用户自定义的控制消息。
为了适应一些控制算法,一些协议的行为需要被定制。例如,一个控制算法可能对数 据包的应答方式敏感。可组合的UDT提供必要的协议配置API接口,用来处理这种敏感问题。
它允许用户定义:如何在接收端响应接收到的包。函数setACKTimer和
setACKInterval决定了,一个ACK控制包,在运行时间里或到达包数量下,多长时间被发 送出去一次。
sendCustomMsg方法,用于将用户自定义的控制包发给UDT连接的对等实体。然后, 对等实体通过调用回调函数processCustomMsg来处理自定义的控制包。
最后,可组合的UDT也允许用户修改RTT(往返时延)和RTO(超时重传时间)。一个新的 拥塞控制类可以选择使用,UDT提供的RTT值或者重新计算的值。同样,RTO值也可以被重 新定义。
允许可配置协议栈的用户自定义控制包,是有必要的。
因为可组合的UDT库,主要集中于研究拥塞控制算法。而且,可以对控制包的定制化 进行限制。数据包的处理会提高CPU的利用率,并且定制的数据包可能会对性能有损害。
用户可以使用UDT控制包头部里的Extend Type信息,来定制专用的控制包。详细的 控制包信息的变化依赖于包Type域的值。
在接收端,用户需要重写processCustomMsg,用以告知UDT如何处理这些新类型 的包。
协议的性能信息用于支持对控制算法的决策和诊断。例如,一些算法,为了调整未来的 发包速率,需要了解一些历史信息。同时,在测试新算法时,还需要性能统计信息和协议内 部参数信息。
性能监控器提供许多信息,包括连接建立后的持续时间,RTT,发包速率,接包速率, 丢包速率,发包周期,拥塞窗口大小,流量窗口大小,ACK包累计值和NAK包累计值。当 这些信息值发生改变时,UDT会记录这些值轨迹。
这些性能轨迹信息可以从3个范畴下读取(如果适用)。
1,连接建立后的合计总值。
2,轨迹被查询时的本地值。
3,轨迹被查询时的瞬时值。
UDT的拥塞控制是一个公开的框架,以便于用户可以容易地实现自定义的控制算法, 同时还可以在多个控制算法之间切换。另外,UDT的原生控制算法的实现过程很详细。
自定义的算法,可以重新定义许多控制流程,也可以调整许多UDT参数。
这些控制流程,可以被某一个事件触发调用。例如,当ACK事件被触发时,控制算法 可以增加拥塞窗口的大小。
UDT允许用户访问2个拥塞控制参数:拥塞窗口大小和包之间的发送间隔。用户可以 调整这2个参数,用以实现基于窗口的控制,基于速率的控制或者混合的方式。
另外,以下参数也会公开给用户。
1) 往返时延(RTT)
2) 最大包大小(Maximum Segment/Packet Size)
3) 估计带宽(Estimated Bandwidth)
4) 最近的已被发送的包序列号(The latest packet sequence number that has been sent so far)
5) 接收端包到达的速率(Packet arriving rate at the receiver side) UDT的实现同样也可以公开一些额外的参数。这些参数信息,可以作为调整包发送速 率的控制要素,被用于用户自定义的拥塞控制算法中。
以下控制事件可以通过CCC(比如通过回调函数),被重新定义:
1) init:当UDT Socket连接完成建立。
2) close:当UDT Socket被关闭。
3) onACK:当接收到ACK应答包。
4) onLOSS:当接收到NAK控制包。
5) onTimeout:当超时发生。
6) onPktSent:当一个数据包被发送。
7) onPktRecv:当接收到一个数据包。
用户还可以在自定义的控制算法里调整以下的参数:
1) ACK间隔:一个ACK控制包,每间隔固定个数(默认是16个)的包,会被发送一次。
用户可以定义间隔包的个数。如果间隔值是-1,那么ACK控制包的发送 将不再基于间隔包的个数。
2) ACK定时器:一个ACK控制包,每间隔固定时间将被发送一次。这个发送被UDT托 管。这个固定时间间隔默认最大值是SYN。
3) 超时重传时间(RTO):UDT计算RTO的算法是4 * RTT + RTTVar。用户可以重新定 义该算法。
当没有用户自定义的算法被实现和配置时,UDT将使用默认的原生控制算法。UDT原 生控制算法应当利用CCC来执行。
UDT原生算法是一个混合的拥塞控制算法。它不仅调整拥塞窗口的大小,也改变包间 的发送间隔。算法使用基于定时器的ACK,并且ACK的时间间隔是SYN。
拥塞窗口初始大小是16个包,包间的时间间隔是0。
原生算法启动时处于慢启动阶段,一直等到第一个ACK或者NAK控制包到达才退出 该阶段。
当接收到ACK控制包时:
1) 如果当前处于慢启动阶段,将拥塞窗口大小设置为:包到达速率和(RTT + SYN) 的乘积。慢启动结束。停止。
2) 设置拥塞窗口大小(CWND)为:CWND = A * (RTT + SYN) + 16。
3) 在下一个SYN周期被增加的发包数(inc)估算描述为:
If (B <= C)
inc = 1/PS;
else
inc = max(10^(ceil(log10((B-C)*PS*8))) * Beta/PS, 1/PS);
B是估计的链路容量,C是当前发包速度。二者的单位是:每秒包数。PS是以字节单位 的固定的UDT包大小。Beta是一个常量值:0.0000015。
4) SND周期被更新为:SND = (SND * SYN) / (SND * inc + SYN)
有4个参数用来控制速率的降低。这些参数的初始化值放在圆括弧中:
AvgNAKNum (1),NAKCount (1),DecCount(1),LastDecSeq (初始序列号减 1)。
UDT里,“一个拥塞周期”解释为:是介于 2个NAK 应答包的周期值,并且在 2个 24
NAK包之间,第一个最大丢包的序列号应当大于LastDecSeq(当最后一次发包速率降低 时,该值是最大的序列号)。
AvgNAKNum是在一个拥塞周期里,NAK包的平均包数。
NAKCount是在当前拥塞周期里,NAK包的累计包数。
当接收到NAK控制包时:
1) 如果处于慢启动阶段,设置包间的间隔时间为 1 / recvrate。慢启动结束。停止。
2) 如果当前NAK 开启一个新的拥塞周期,增加包间的间隔时间(snd)为:snd = snd * 1.125 ;更新AvgNAKNum,复位NAKCount 为1,然后在1 和 AvgNAKNum范围内计算随机数DecRandom。更新LastDecSeq。停止。
3) 如果DecCount <= 5,并且NAKCount == DecCount * DecRandom:
更新SND周期:SND = SND * 1.125;
DecCount自增1;
记录当前最大的被发送的序列号(LastDecSeq)。