
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
B/S开发模式是指客户端运行在网页里,运行受限于浏览器,展示的结果也只能在浏览器范围里呈现。这种方式是一种发展非常成熟的模式,优点很多,这里不进行详细表述。但是这个模式有些缺点:
1、B只能向S请求,S不能向B主动推送内容,这是Web服务的本质规定。现在有一定的新技术在探索,但是模式复杂,有些细节也不清晰。
2、显示只能控制在浏览器里,但是浏览器的展示能力有限,有时候不能满足客户的要求。
针对现在这样的缺陷,现在出现了用软件来监听网页分析网页统计网页数据的趋势,也导致了网页保护技术的产生。网站设计者在满足浏览基本要求的情况下,加大软件下载网页的难度,不让软件轻易访问网站,进而降低网站服务器的压力。在这些技术里,Frame保护技术是经常用的。
在HTML标准里Frame可以带子URL,在Frame宿主的网页加载后,浏览器保存的文本只是描述Frame的文本,并不会包含Frame里的文本,下面是一个受Frame保护的网页的源文件内容:
<frameset rows="89,*, 25" border="0" framespacing="0" frameborder="no">
<frame src="_Header/Header.aspx" noresize="noresize" scrolling="no" frameborder="0" id="frHeader" name="frHeader" />
<frameset cols="220,*" border="0">
<frame src="_Menu/Menu.aspx" scrolling="auto" id="menu" name="menu" noresize="noresize" frameborder="0" />
<frame src="Member/CB/CB.aspx?sa=1" id="main" name="main" scrolling="auto" noresize="noresize" frameborder="0" />
</frameset>
<frame src="../Foot.html" noresize="noresize" scrolling="no" frameborder="0" id="frter" name="frFooter" />
</frameset>
但是浏览器客户区里明显显示的内容是非常多的,并不是只有上面这些。
关键字:C# WebBrowser HtmlDoucment HTML Frame TABLE 网页自动化 网页分析 网页监控
我们锐英源在2010年11月份承接了一个网页自动化监听及分析报警系统的外包。在解决技术难题时,就遇到了Frame保护难题和Table表数据插入乱数据解析难题,本文讲解了Frame保护技术是如何破解的,对于Table表数据插入乱数据技术这里不讲解。
在讨论解决之前,说一个本质上的区别:Frame保护技术并不是让浏览器不去获取Frame里的内容,只是让程序员直接获取变为不可能。直接获取不可能,就要变通,进行间接的获取。
浏览器在加载Frame过后,肯定是要再对每个Frame进行再次加载,再次加载时,会使用Frame的URL来浏览获取网页内容并显示到Frame所在位置。
上面的描述隐含了2层意思:
1、如果Frame没有加载完成时,你去获取Frame的源文件肯定出错。
2、通过主网页的HtmlDocument来获取内容,肯定是没有Frame里的源文件的。
问题讲透了,大家也就理解怎样解决问题了。
WebBrowser的DocumentCompleted事件,会在控件完成加载文档时发生。这也是MSDN上的直接解释。MSDN的详细解释如下:
每当设置以下属性或调用以下方法之一时,WebBrowser 控件都会导航到新文档:
Url
DocumentText
DocumentStream
Navigate
GoBack
GoForward
GoHome
GoSearch
处理 DocumentCompleted事件,在新文档完成加载时接收通知。如果 DocumentCompleted事件发生,则新文档已完全加载,这意味着可以通过 Document、DocumentText 或 DocumentStream 属性访问该文档的内容。
上面一段话的意思是说,调用列表里的方法,就会有文档加载事件触发。触发时就可以访问内容了,可以访问也就可以找到Frame对应的URL,有了URL就可以直接浏览,获取内容了,下面是直接浏览的方法的代码(记住一定要在DocumentCompleted里使用):
//锐英源孙老师封装的函数,加载Frame里的URL来获取Frame数据
//参数surl就是Frame里的URL
//wbFrameTemp是临时的WebBrowser控件
void StartFakeWB(System.Uri surl)
{
if (wbFrameTemp!=null)//如果不为空要记的释放,不释放,肯定不能长时间运行的,这是MSDN上强调的有的
{
wbFrameTemp.Dispose();//释放
wbFrameTemp = null;//置空
}
wbFrameTemp = new WebBrowser();//新建
wbFrameTemp.Url = surl;//指定URL
wbFrameTemp.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(wb_DocumentCompleted);//事件绑定
}
下面是调用的代码的说明:
StartFakeWB(datawebBrowser.Document.Window.Frames["home"].Document.Window.Frames["content"].Url);
当然你还要写临时控件的DocumentCompleted的事件函数:
void wb_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
string sContent = "";
sContent = wbFrameTemp.DocumentText.ToString();//这里通过DocumentText就可以获取到了
}
这里要提示一个细节WebBrowserReadyState。在MSDN里对DocmentCompleted事件的解释页面里,第一页是没有提到这个状态的。但是这个状态对这个DocumentCompleted的使用是有影响的,下面看下MSDN里的说明:
|
成员名称 |
说明 |
|
Uninitialized |
当前未加载任何文档。 |
|
Loading |
该控件正在加载新文档。 |
|
Loaded |
该控件已经加载并已初始化新文档,但尚未接收到所有文档数据。 |
|
Interactive |
该控件已加载足够的文档以允许有限的用户交互,比如单击已显示的超链接。 |
|
Complete |
该控件已完成新文档及其所有内容的加载。 |
在实际使用DocumentCompleted里,会发现WebBrowser的.ReadyState并不全是Complete状态,会有其它状态,所以必须在ReadyState为Complete时才能调用子URL技术的代码,这些可以参考完整的例子代码。
上面讲过HtmlDocument的DocumentText是不包含Frame的内容的,但是浏览器里还能显示所有内容,这中间的的差异肯定有人会觉得奇怪。其实HtmlDocument里是包含了显示内容的所有HTML标签的,只是它是通过几层子对象来实现的。
在HtmlDocument里把Frame理解为Window,Window里有URL,也就可以有子的HtmlDocument。对于初学者来说,理解这个可能有些困难,理解困难时就从基本面来想,静态网页设计里,一个TABLE里TD的子标签还可以是个TABLE,在HtmlDocument里组织各个子对象,也可以象这样,各个标签对应的对象本身也是个容器,容器里当然可以容纳对象了。容纳的对象的类型,只要满足类型的要求就可以了。
在上面示例代码里有一行代码:
StartFakeWB(datawebBrowser.Document.Window.Frames["home"].Document.Window.Frames["content"].Url);
这行代码的意思是:主网页里有home框架Frame,home下还有content框架Frame。在主网页加载完后,home框架的Document已经是加载好的,里面的标签对象都是可以找出来用的。所以你能遍历主网页的Document,也就在主网页加载完成后,遍历主网页里子Frame的Document了。
遍历的代码请看下面例子:
private HtmlElement FindControlByHTMLAndTag(string shtml, HtmlElementCollection listOfHtmlControls,string sTag)
{
foreach (HtmlElement element in listOfHtmlControls)
{
if (!string.IsNullOrEmpty(element.OuterHtml) && !string.IsNullOrEmpty(element.TagName))
{
string stname = element.OuterHtml;
if (element.TagName==sTag)
{
if(stname.IndexOf(shtml)>=0)
return element;
}
}
}
return null;
}
本例子对应的源代码是VS2008编写,编译运行后会看到如下界面:
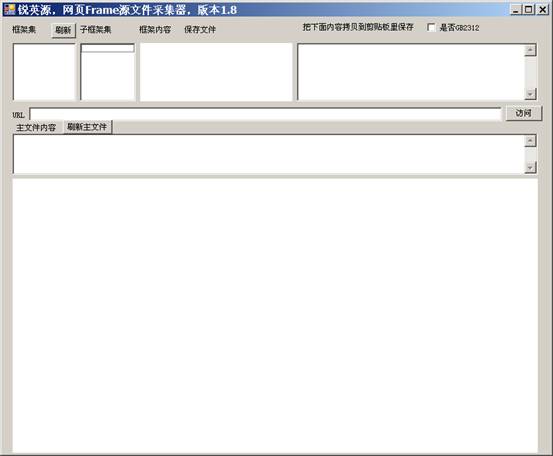
各个部分操作说明:
1、访问按钮,点击后浏览URL框架框里的网站。
2、最下面WebBrowser控件会显示网页内容。
3、控件加载结束后,在框架集里会显示网页里会有哪些框架。
4、双击框架集里一行,进行选择子框架或显示框架。
5、如果双击框架集里行有子框架,则子框架集会显示子框架。如果没有,则在右边窗口里显示内容。
6、双击子框架集里的一行,可以显示子子框架里的内容。
7、网页里有汉字的话,如果是GB2312的编码,请对“是否GB2312”打勾,否则请去掉勾。如果选择不对,网页里的汉字会有乱码。
源代码大家可以随意使用,在使用时请保留出处注释。