
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
服务方向
联系方式
内容来自国外pdf,对理解三音素聚类和决策树有帮助,翻译内容很形象,希望对大家有用。
Lab 3: Word recognition and triphone models
University of Edinburgh
February 5, 2018
So far we have been working with phone recognition on TIMIT. In this lab
we will move instead to word recognition. This requires a word-level language
model, for which we will be using the Wall Street Journal (WSJ) language model.
Path errors
If you get errors such as command not found, try sourcing the path again:
source path.sh
In general, every time you open a new terminal window and cd to the
work directory, you would need to source the path file in order to use any
of the Kaldi binaries.
There is an appendix at the end of every lab with the most typical mistakes.
Let’s begin by opening a terminal window, cd to your workdir and sourcing the
path:
cd ~/asrworkdir
source path.sh
Before we start building new models run the following script to gather some
new files we need to do word recognition:
./local/lab3_setup.sh
The message \lab 3 preparation succeeded" should appear.
When you ran the above command it will have generated a new language model directory: data/lang wsj, new training and test directories, and a monophone experiment directory that we have trained for you already.当您运行上述命令时,它将生成一个新的语言模型目录:data / lang wsj,新的培训和测试目录以及一个我们已经为您培训的单音素实验目录。
There’s a crucial difference to the new language model directory from the previous one. Compare the words.txt file in each:新的语言模型目录与以前的目录有一个关键的区别。比较每个文件中的words.txt文件:
less data/lang/words.txt
less data/lang_wsj/words.txt
What is different between the two? Let’s also have a look at the new phoneset:
less data/lang_wsj/phones.txt
Our phones are now dependent upon where they occur in the words. For anexplanation of the suffixes, see现在,我们的音素取决于它们在单词中出现的位置。有关后缀的说明,请参见
less data/lang_wsj/phones/word_boundary.txt
To see how this relates to the lexicon, open the following file:
less data/lang_wsj/phones/align_lexicon.txt
Now search (remember /) for \^ SPEECH", which will show the first occurrence of a word that starts with \SPEECH". How does the mapping relate to the position-dependent phones we saw above?现在搜索(记住/)以查找\\ ^ SPEECH“,这将显示以\\ SPEECH”开头的单词的第一次出现。映射与我们在上面看到的与位置相关的音素有何关系?
Finally, have a look at the new training directory which now maps fromutterance to words instead of phones:最后,看看新的培训目录,该目录现在将话语映射到单词而不是音素:
less data/train_words/text
1.2 Monophone models
We have provided monophone models and alignments, as well as a decode on the test set. These are placed in exp/words/mono and exp/words/mono ali.我们提供了单声道音素模型和对准,以及测试集上的解码。这些放在exp / words / mono和exp / words / mono ali中。
Have a look at the score for the decode on the test set:看一下测试集上解码的得分:
more exp/word/mono/decode_test/scoring_kaldi/best_wer
more
The command more is very similar to less, apart from that it prints the output to the console directly.Ok! There’s lots of room for improvement...
1.3 Triphone models
Let’s start training a triphone model with delta and delta-delta features.
Backslashes
Backslashes in Bash (n) which is present in the next box, are simply away of splitting commands over multiple lines. That is, the following two commands are identical:
some_script.sh --some-option somefile.txt
and
some_script.sh --some-option \
somefile.txt
You may remove the backslash and type these commands on a single line.But sometimes when writing scripts, avoiding too long commands on asingle line can help readability.
Be careful about spaces after n. Bash will expect a newline immediately, and a space here before the newline will make a script crash.
Run the following command to train a triphone system. This might take a few minutes...
steps/train_deltas.sh 2500 15000 data/train_words \
data/lang_wsj exp/word/mono_ali exp/word/tri1
• While that is running, open another terminal window, change directory to the work directory and source the path.
1.4 Delta features
Above we started running a script called train deltas.sh. This trains triphone models on top of MFCC+delta+deltadelta features. To avoid having to store features with delta+deltadelta applied, Kaldi adds this in an online fashion,just as another pipe, using the programme add-deltas. Remember how we checked the feature dimension of the features in the first lab? Run the following command.
feat-to-dim scp:data/train/feats.scp -
What do you expect the dimension to be be after applying add-deltas?
Run the following command.
add-deltas scp:data/test/feats.scp ark:- | feat-to-dim ark:- -
1.5 Logs
Kaldi creates detailed logs during training. These can be very helpful when things go wrong. By now we should have some of the first ones created for the triphone training:
less exp/word/tri1/log/acc.1.1.log
Notice that on the top, the entire command which Kaldi ran (as set out by the script) is displayed. For this example it runs a command called gmm-acc-stats-ali,and then if you look closely there is a feature pipeline using the programmes apply-cmvn and add-deltas which applies these transforms and additions to the features in an online fashion.请注意,在顶部,显示了Kaldi运行的整个命令(如脚本所示)。在此示例中,它运行一个名为gmm-acc-stats-ali的命令,然后如果您仔细观察,就会发现一个功能管道,该管道使用apply-cmvn和add-dels程序以在线方式将这些转换和添加应用于功能。
1.6 Triphones
When we ran the triphone modelling script above we also passed two numbers,2500 and 15000. These are respectively the number of leaves in the decision tree and the total number of Gaussians across all states in our model.当我们在上面运行triphone建模脚本时,我们还传递了两个数字2500和15000。这两个数字分别是决策树中的叶子数和模型中所有状态之间的高斯总数。
Triphone clustering
As you may recall from the lectures, having a separate model for each triphone is generally not feasible. With typically 48 phones we would require 48 × 48 × 48, i.e. more than 110000 models. We don’t have
enough data to see all those, so we cluster them using a decision tree. The number of leaves parameter then sets the maximum number of leaves in the decision tree, and the number of gaussians the maximum number of Gaussians distributed across the leaves. So on average our model will have an average of numleaves numgauss Gaussians per leaf.
您可能会在讲座中回忆到,为每个三音素单独设置模型通常是不可行的。对于典型的48个音素,我们将需要48×48×48,即超过110000个型号。我们没有足够的数据来查看所有这些数据,因此我们使用决策树对其进行聚类。然后,叶子数参数设置决策树中的最大叶子数,而高斯数则是在叶子上分布的最大高斯数。因此,平均而言,我们的模型平均每片叶子有numleaves/numgauss个高斯。
To see how many states have been seen, run the following command:
sum-tree-stats --binary=False - exp/word/tri1/1.treeacc | head -1
4
The first number indicates the number of states with statistics. Dividing that number by three will roughly give the number of seen triphones (why is this?).第一个数字表示带有统计信息的状态数。将该数字除以三将大致得出所看到的三音素的数量(这是为什么?)。
Let’s have a closer look at the clustering in Kaldi. It’s also a good opportunity to look a bit deeper at the Kaldi scripts. Open the training script we justran by typing让我们仔细看看Kaldi中的聚类。这也是一个深入了解Kaldi脚本的好机会。通过键入以下内容打开我们刚才运行的训练脚本:
less steps/train_deltas.sh
At the top is a configuration section with several default parameters. These are the parameters that the script can take by passing --param setting to the script when running it. Most scripts in Kaldi are set up this way. The first one is a variable called stage, this can be really useful to start a script partway through. Scroll down till line 88 which says顶部是带有几个默认参数的配置部分。这些是脚本可以通过在运行脚本时将--param设置传递给脚本来采用的参数。 Kaldi中的大多数脚本都是以这种方式设置的。第一个是称为stage的变量,这对于在途中启动脚本非常有用。向下滚动到第88行,该行显示
if [ $stage -le 2 ]; then
This is saying that if the stage variable is less than or equal to two, run this section. This is the section that builds the decision tree. It first calls a binary called cluster-phones, this uses e.g. k-means clustering to cluster similar phones. These clusters will be the basis for the questions in the decision tree.这就是说,如果阶段变量小于或等于2,请运行此部分。这是构建决策树的部分。它首先调用一个称为集群音素的二进制文件,它使用例如k均值聚类以聚类相似的音素。这些群集将成为决策树中问题的基础。
Kaldi doesn’t use predefined questions such as \is the left phone a fricative?",but rather estimates them from the data. It writes these using the numeric phone identities to a file called xp/word/tri1/questions.int. Let’s look at it using a utility that maps the integer phone identities to their more readable names. Leave less by pressing q and run the next command:卡尔迪不使用预定义的问题,例如\\左手机是否是摩擦符号?“,而是根据数据进行估算。它使用数字音素身份将这些信息写到名为xp / word / tri1 / questions.int的文件中。使用将整数音素身份映射到其更易读的名称的实用程序来查看它。按q并运行下一个命令,以使它变少。
utils/int2sym.pl data/lang_wsj/phones.txt \
exp/word/tri1/questions.int | less
Each line is a cluster. Some of these clusters are really large, but hopefully some of them should make sense. We use these to build a clustering tree, stored in exp/word/tri1/tree. Exit less and run the following command:每行是一个群集。这些集群中的一些确实很大,但希望其中一些应该有意义。我们使用它们来构建一个聚类树,存储在exp / word / tri1 / tree中。退出less并运行以下命令:
copy-tree --binary=false exp/word/tri1/tree - | less
This file sets out the entire clustering tree. We’ll only get a gist of what it represents by looking at a few lines. The further down this file, the deeper we move into the tree. Move down to line 50 by typing the following letters on the keyboard while in less:该文件列出了整个群集树。我们只看几行就可以大致了解它所代表的含义。该文件越向下,我们进入树的深度就越大。在不到的情况下,通过在键盘上键入以下字母,向下移至第50行:
50g
You should see a line that says
SE 0 [ 40 41 42 43 92 93 94 95 96 97 98 99 228 229 230 231 ]
The numbers in the brackets are phones. By now you should be able to figure out which phones these represent (hint: language directory). SE stands for \SplitEventMap", which is essentially a split in the tree. The following number is typically either 0, 1, or 2, and they stand for left, centre and right.That is, for this line we are asking whether the left (0) phone is one of 40, 41,42, ..., 231. If that is true, we括号中的数字是音素。到目前为止,您应该能够弄清楚这些音素代表哪些音素(提示:语言目录)。 SE代表\\ SplitEventMap“,本质上是树中的一个拆分。以下数字通常是0、1或2,它们分别代表left,center和right。也就是说,对于这一行,我们要询问是否左(0)音素是40、41、42,...,231之一。如果是这样,我们
• proceed to the next line, asking whether the left phone is one of [40,41,42,43],if that is true we•转到下一行,询问左侧音素是否为[40,41,42,43]之一,如果是,我们
• proceed to the next line, this time asking whether the right (2) context is one of [1,2,3,4,5] (which phone is this?)•转到下一行,这一次询问右(2)上下文是否为[1,2,3,4,5]中的一个(这是哪个音素?)
Finally, we proceed to the next line where CE stands for a ConstantEventMap and indicates a leaf in tree. If our previous question was true then we choose pdf-id 1302, and if not, we choose 1091. The subtree we have been looking at is illustrated in Figure 1. Can you tell how we would get pdf-id 1039?最后,我们进入下一行,其中CE代表ConstantEventMap,并指示树中的叶子。如果我们先前的问题是正确的,那么我们选择pdf-id 1302,否则,我们选择1091。我们一直在看的子树如图1所示。您能告诉我们如何获得pdf-id 1039吗?
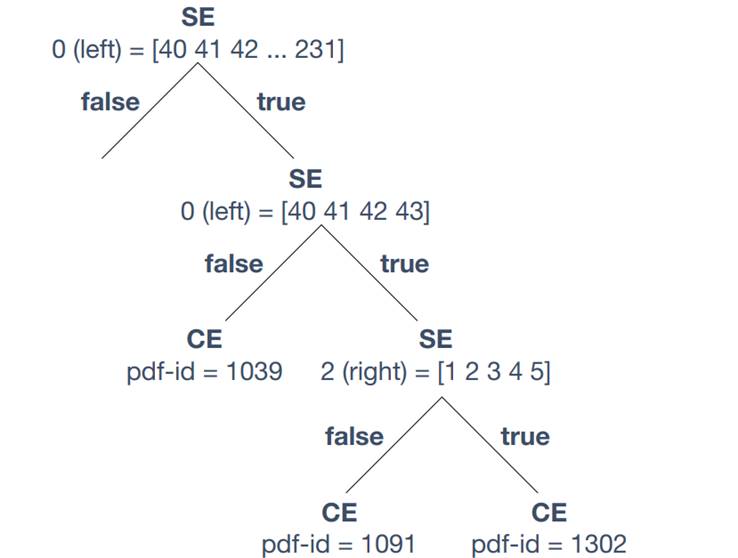
Figure 1: Tree clustering example
Ok, by now the triphone system should have finished training. Let’s create a decoding graph and decode our triphone system, this may take a few minutes:
utils/mkgraph.sh data/lang_wsj_test_bg \
exp/word/tri1 exp/word/tri1/graph
steps/decode.sh --nj 4 exp/word/tri1/graph \
data/test_words exp/word/tri1/decode_test
When the decoding have finished, score the directory by running:
local/score_words.sh data/test_words exp/word/tri1/graph \
exp/word/tri1/decode_test
We can then have a look at the WER by typing:
more exp/word/tri1/decode_test/scoring_kaldi/best_wer
That should be considerably better than the monophone system, but there’s still lots of room for improvement. The typical progression in Kaldi would now be to train a system on top of decorrelated features and then train a system with speaker adaptive training. But that’s for another lab...
We’re done! Next time we’ll look at training hybrid neural network models.
1.7 Appendix: Common errors
• Forgot to source path.sh, check current path with echo $PATH
• No space left on disk: check df -h
• No memory left: check top or htop
• Lost permissions reading or writing from/to AFS: run kinit && aklog.
To avoid this, run long jobs with the longjob command.
• Syntax error: check syntax of a Bash script without running it using bash
-n scriptname
• Avoid spaces after nwhen splitting Bash commands over multiple lines
• Optional params:
• command line utilities: --param=value
• shell scripts: --param value
• Most file paths are absolute: make sure to update the paths if moving
data directories
• Search the forums: http://kaldi-asr.org/forums.html
• Search the old forums: https://sourceforge.net/p/kaldi/discussion
7
1.8 Appendix: UNIX
• cd dir - change directory to dir, or the enclosing directory by ..
• cd - - change to previous directory
• ls -l - see directory contents
• less script.sh - view the contents of script.sh
• head -l and tail -l - show first or last l lines of a file
• grep text file - search for text in file
• wc -l file - compute number of lines in file