
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
锐英源翻译文章,信息来源于codeproject,加上注解使大众更好学习
LSTM已经成熟,各个开源组件里都有源代码,一般人也只是用就可以了。普通人要用了,也就是掌握输入输出,本文里有一些特别高级的数据结构,比如opencv捕获出的视频序列在python里怎么表达,视频序列用np.expand_dims转换,转换的数组形式通过[]的层次可以理解。train.py里调用了fit,而LSTM封装在了model.py里,model.py里调用了库里的LSTM。
下面是翻译正文,有想研究细节的朋友可以加我聊,左边有联系方式。
在本文中,我们将解释 RNN 和长短期记忆网络的原理,它们是 RNN 的一种变体。我们还将分享我们在基于 RNN-LSTM 的视频图像目标监控方面的经验。本文将对从事图像分类项目的开发人员以及仅考虑使用神经网络进行视频处理的开发人员有所帮助。
在我们之前的一篇文章中,我们讨论了对单独图像进行分类的问题。当我们试图在视频录制中将广告与足球比赛区分开来时,我们需要让神经网络在分析当前帧的同时记住之前帧的状态。
幸运的是,这个问题可以通过循环神经网络或 RNN 来解决。这些神经网络包含递归关系:每个进一步的输出取决于先前输出的组合。RNN 应用于广泛的任务,包括语音识别、语言建模、翻译和音乐生成。
与所有输入数据独立于输出数据的传统神经网络不同,循环神经网络 (RNN) 使用上一步的输出作为当前步骤的输入。RNN 还提供了在输入和输出中处理向量序列的机会。此功能允许 RNN 记住数据序列。您可以在Andrej Karpathy的文章The Unreasonable Effectiveness of Recurrent Neural Networks中找到有关 RNN 有效性的更多详细信息以及它们可以实现的目标。
让我们考虑如何应用 RNN。在传统神经网络的基本情况下,为神经网络提供一个固定大小的输入,并为这组数据获得输出。例如,我们为网络提供单个图像并仅接收该图像的分类结果。RNN 允许我们使用数据向量序列进行操作,其中输出取决于先前的分类结果。以下是循环网络如何运作的示例:
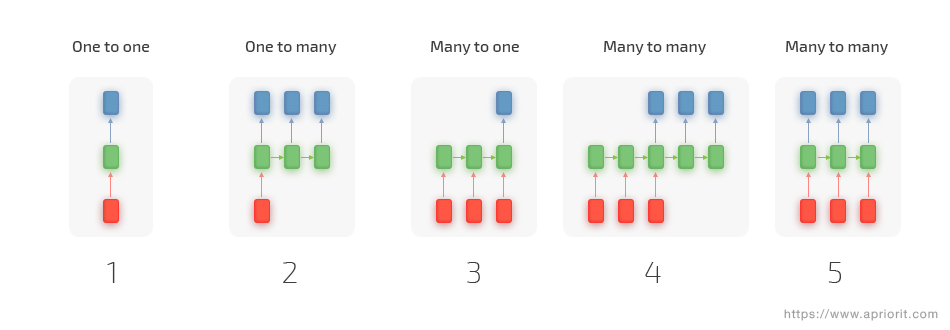
每个矩形都是一个向量,箭头代表函数。输入向量是红色的,而输出向量是蓝色的,绿色向量保持 RNN 的状态。
然而,随着分析数据与先前输出之间差距的增加,RNN 往往会失去其有效性。这意味着尽管 RNN 对处理序列数据进行预测很有效,但循环网络只有短期记忆。这就是为什么与 RNN 一起,研究人员开发了长短期记忆 (LSTM) 架构来解决丢失长期依赖关系的问题。通过使计算更新方程的数学模型复杂化以及通过更有吸引力的反向传播动力学来克服这一挑战。
简而言之,在 LSTM 中,通过让隐藏层中的每个神经元执行四次操作而不是一次操作来解决丢失长期依赖关系的挑战。让我们看看 LSTM 是如何工作的:
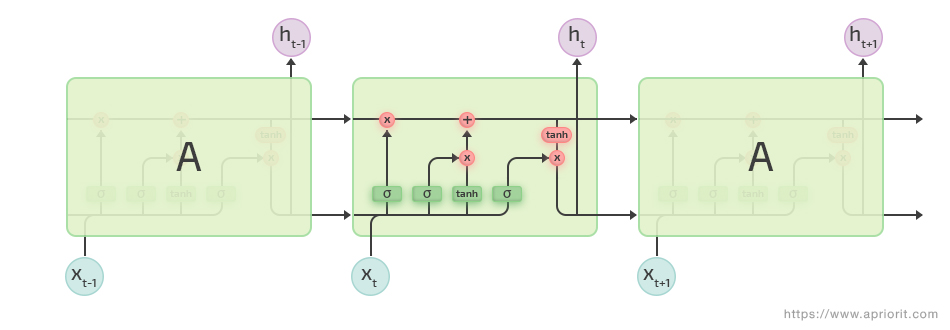
LSTM 具有称为门的内部机制,可以调节信息流。在训练过程中,这些门会了解序列中哪些数据对保留很重要,哪些数据可以忘记。这允许网络将相关信息传递到长序列序列中以进行预测。您可以在此处找到有关 LSTM 操作原理的更多详细信息。
现在让我们看看如何在数据序列上训练 LSTM。我们将使用这个存储库来研究各种循环网络(包括 LSTM)的性能。我们将使用 Python 3、TensorFlow 和 Keras——以及ffmpeg——以形成一个数据集,以使用存储库和实现我们的分类器。我们建议在 Google Colab 中进行所有调查,因为它们需要大量硬件资源。
本文中提供的所有脚本和示例都可以在此处找到。
我们将继续研究我们在上一篇文章中看到的视频样本,我们需要将足球比赛录制分为广告和足球比赛剧集。
要剪切一组短视频序列,可以使用以下ffmpeg命令:
ffmpeg -i Football.mp4 -ss 00:00:00 -t 00:00:03 Football_train_1.mp4
此命令提取Football.mp4开头的前三秒,并创建一个名为Football_train_1.mp4的新视频文件。最好将视频切割成相等的时间间隔,以便在每个序列中获得相同数量的帧。准备好后,将视频dataset文件放在以下文件夹结构中:
/data --- /train | | | --- /Football | | Football_train_1.mp4 | | Football_train_2.mp4 | | ... | | | --- /Commercial | Commercial_train_1.mp4 | Commercial_train_2.mp4 | ... --- /test | | | --- /Football | Football_test_1.mp4 | Football_test_2.mp4 | ... | | | --- /Commercial | Commercial_test_1.mp4 | Commercial_test_2.mp4 | ...
创建两个反映数据类型的子文件夹:测试或训练。准备好数据集后,运行extract_files.py脚本,该脚本从每个媒体文件中提取一系列视频帧,并将它们保存为具有相应名称的图像。此脚本将媒体文件的扩展名作为参数:
python extract_files.py mp4
运行此脚本后,数据目录将包含一个data_file.csv文件,该文件显示每个视频中的帧数。
为了开始训练 LSTM 网络,请运行带有帧序列长度、类限制以及帧高度和宽度的参数的train.py脚本。例如,假设我们要在Football.mp4中的两个类别的 75 帧序列上训练我们的网络,分辨率为 1280х720。
python train.py 75 2 720 1280
训练后,data/checkpoints 目录将包含权重文件。训练的最后一次迭代将提供具有最高准确度的.hdf5权重文件。让我们将此文件移动到具有clasify.py脚本的文件夹中,并将其命名为lstm-features.hdf5。在我们开始使用预训练网络之前,让我们看一下我们将使用的脚本,看看它们在训练阶段是如何工作的:
在训练阶段,Extractor对象会创建一个在数据集上进行初步训练的InceptionV3ImageNet模型,并将其应用于视频序列中的每个图像。作为图像识别过程的结果,它从每张图像中提取特征,然后将其收集到扩展名为.npy的新序列文件中。最后,data/sequences 文件夹将为每个视频文件包含一个新的特征序列文件。
下一步是训练新ResearchModel()对象,它是来自Keras的LSTM对象。训练的中间结果被收集到权重文件中并保存在 data/checkpoints 文件夹中。训练模型直到分类准确率在接下来的五次迭代中提高。
在我们的网络训练好之后,我们可以开始对帧序列进行分类。为此,我们将使用带有以下参数的clasify.py脚本:
python clasify.py 75 2 lstm-features.hdf5 video_file.mp4
我们的分类结果会保存在result.avi文件中。
让我们看看视频文件分类脚本是如何工作的。它的作用类似于train.py脚本。
使用OpenCV库分析视频文件。经过分析,我们接收帧大小并初始化 OpenCV 以读取和记录/写入视频帧。
capture = cv2.VideoCapture(os.path.join(video_file))
width = capture.get(cv2.CAP_PROP_FRAME_WIDTH) # float
height = capture.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
fourcc = cv2.VideoWriter_fourcc(*'XVID')
video_writer = cv2.VideoWriter("result.avi", fourcc, 15, (int(width), int(height)))
之后,我们从文件中逐帧读取指定数量的帧序列,并应用InceptionV3进行识别。作为输出,我们得到对象中的一系列基本特征sequence。
# get the model.
extract_model = Extractor(image_shape=(height, width, 3))
saved_LSTM_model = load_model(saved_model)
frames = []
frame_count = 0
while True:
ret, frame = capture.read()
# Bail out when the video file ends
if not ret:
break
# Save each frame of the video to a list
frame_count += 1
frames.append(frame)
if frame_count < seq_length:
continue # capture frames until you get the required number for sequence
else:
frame_count = 0
# For each frame, extract feature and prepare it for classification
sequence = []
for image in frames:
features = extract_model.extract_image(image)
sequence.append(features)
...
在得到基本特征的序列后,我们可以应用我们预训练的LSTM网络进行序列分类。
.
# Classify sequence
prediction = saved_LSTM_model.predict(np.expand_dims(sequence, axis=0))
print(prediction)
values = data.print_class_from_prediction(np.squeeze(prediction, axis=0))
...
现在我们在每张图像的左上角指定分类结果,并编译一个新的视频文件:
for image in frames:
for i in range(len(values)):
cv2.putText(image, values[i], (40, 40 * i + 40),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 255, 255), lineType=cv2.LINE_AA)
video_writer.write(image)
...
重复这个过程,直到视频文件中的所有帧都被分类。
在这里你可以看到我们最终得到了什么。